之前学完了Coursera - Andrew Ng - Machine Learning课程,受益匪浅,对machine learning的很多概念和实际应用有了更深入的理解。不过这个课程时间已经比较久了,那时ml的应用情况和现在应该有了天壤之别,所以内容上有些滞后。不过入门学习的话,还是推荐看一遍该课程。至少与我个人而言,觉得教的非常好,学习内容放在博客中。
Andrew老师最近创办了deeplearning.ai,主页上目前的内容是关于deep learning的课程。课程内容还是放在了Coursera - Andrew Ng - Leep Learning,所以继续学习,记录,总结。
又及,网易云课堂上有免费的专业课,一样的课程,而且上面字幕是中英对照的,看起来比较舒服,但我看了一会发现没有课后问题,也没有编程作业,所以还是转到coursera上学习。因为按我之前学习的经验,课后习题和编程作业非常重要,练习和编程实现可以极大地提高对知识的理解程度。(coursera上课程,7天免费,后面每月付费49刀。)
又及,deep learning课程要求不可以公开作业代码,包括上传到github,所以不整理代码了。😆
深度学习第一门课程: Neural Network and Deep Learning的学习笔记。
相关笔记:
- Neural Network and Deep Learning
- Improving Deep Neural Networks
- Structuring Maching Learning Projects
- Convolutional Neural Networks
- Sequence Models
还有之前记录machine learning学习笔记
Why Deep Learning
为什么deep learning这几年特别厉害?
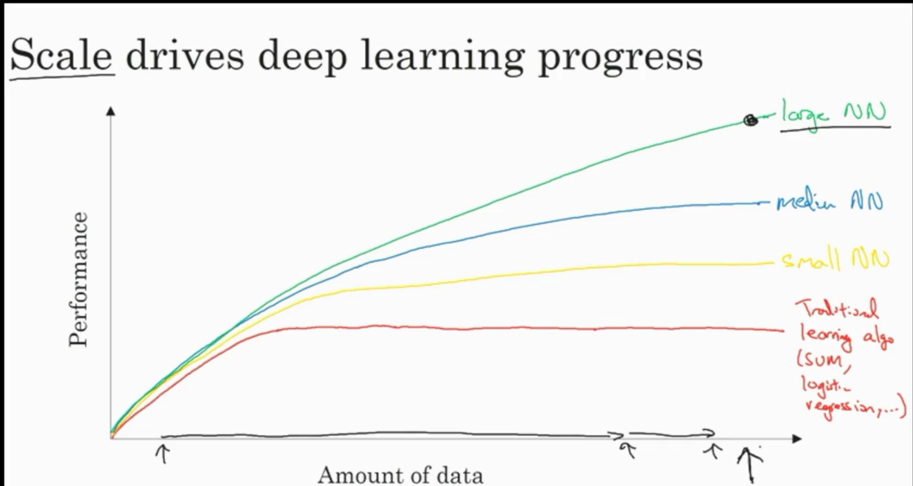
主要归于:海量数据的采集;算法的创新;计算能力的提高。
数据到了一定量级时,神经网络相关算法相比于其它算法拥有统治级的表现。而计算神经网络,需要非常强大的计算能力。
Concept
模型的表示方法和之前学到的略有区别:
- 神经网络模型中将常量(bias node)从参数中去掉而使用新参数,inter-spectrum。
- 单个误差函数记做,lost function,损失函数。

上图体现了微分的级联性质(分级去思考微分确实更容易理解和推导),比如:
两者一结合就可得到:
对logestic模型而言,基本上就是上面的公式,如果要再对具体参数求导,可进一步分层计算,就比较容易分析了。
python的numpy库进行矩阵运算时,会进行broadcasting扩展,就是将矩阵的维度进行自动扩展:
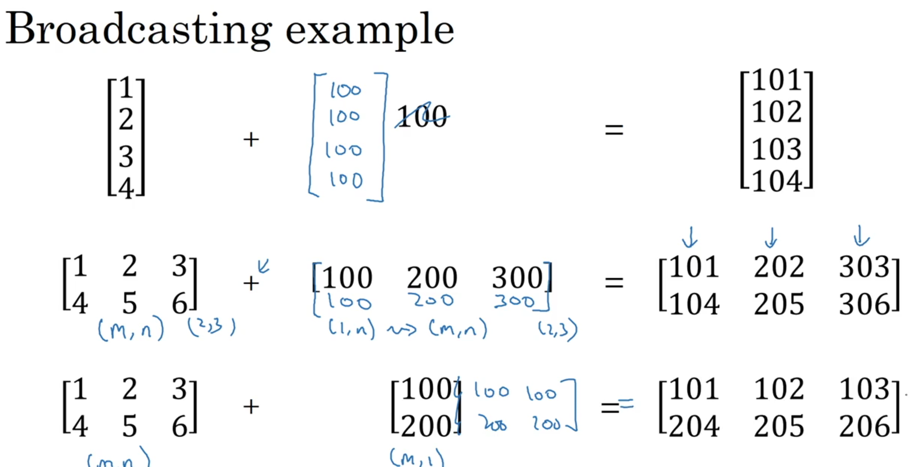
简洁是简洁了,但使用时候,需要更加明确矩阵的维度信息,不要用错了broadcasting。
使用numpy的array,需要留意,如果指定一个维度,那么不是矩阵,而是数组,比如np.random.randn(5)得到的不是向量(矩阵中的概念),而只是数组,如果需要使用向量,要明确指定维度,比如np.random.randn(5, 1)。我觉得这个设定更好,相比于octave/matlab专门用来矩阵运算语言,python使用面更广,区别好矩阵和普通数组显得有必要。同时,明确指定维度也符合python的设计原则:Explicit is better than implicit.
神经网络的模型表示方法也略微变化了一些:
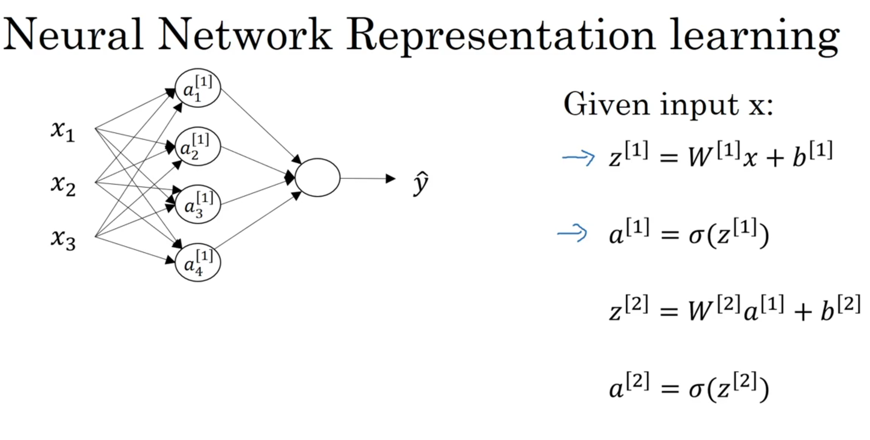
使用中括号表示层级,而小括号中内容表示不同数据,这样子统一了表示。同样,使用常量参数的表现形式更简洁。
activation function有几种形式:
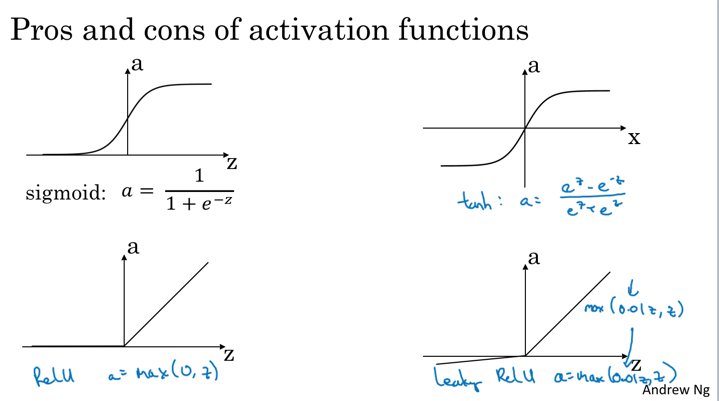
之前主要使用的sigmoid函数只有在二元判定问题上可能使用,大多数时候使用tanh和ReLu。tanh其实是sigmoid的移位函数,但是引入了负数,中值为0,效果更好。而ReLu(rectified linear unit,线性整流函数)是业界使用最多的,兼具了效果和计算效率。最后一种叫做Leaky ReLu,变种,使用不多。
神经网络最难理解的部分是反向传播,按照偏导数的链接性来分析更容易理解:
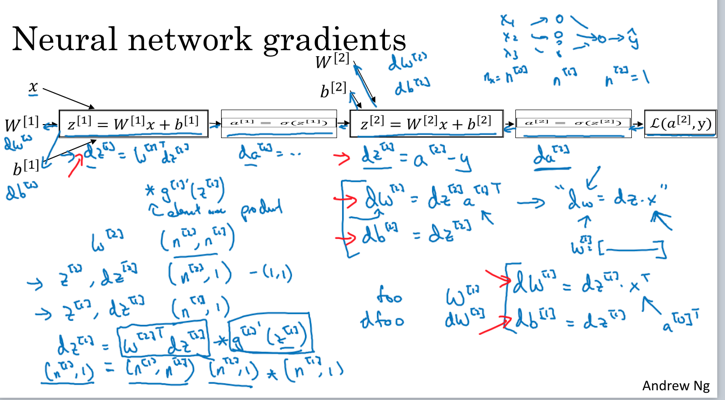
从图中可看出,参数的导数是反着计算的(图中响应函数是sigmoid)。为了求最开始参数对损失函数的导数,先计算其前一个参数的导数,依次推导,反向求解。
最先推理时不考虑数据维度,而只考虑特征维度和层维度(去掉小括号,不考虑有个数据,只考虑一个数据向量),在矩阵方程推导完成后,就可以无缝添加数据维度。添加时,只需要将特征向量横向扩展,不改变之前推导公式的矩阵运算方式(计算结果对求平均)。这样子降维分析降低了推导的难度,也可以想的更清楚。(这需要数据的表达模式统一,数据向量都按照列表示,多数据,就是多列,所有中间结果都按照该框架统一)
两层神经网络的计算公式整理如下(图片截取于课程作业):

一定要注意上面激活函数的区别,在最后一层是sigmoid函数,所以才有(二元判定才使用),但在中间的函数使用的是,其导数是。
如果考虑多层,其计算模型可以抽象为下图(图片截取于课程作业)
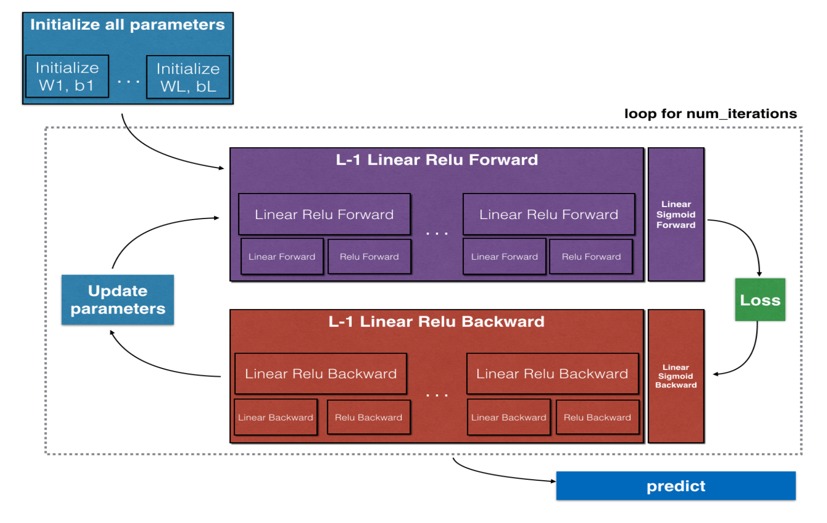
正向计算单元的任务是根据计算得到,而反向计算过程是根据计算得到。正向计算过程中,将缓存,便于后续反向计算导数。
实现技巧之一是将计算函数(正向和方向)都抽象为一个函数/模块:
# 反向计算核心代码 |
实现NN模型的注意点和之前整理的差不多。
其实所谓的Deep neural network就是神经网络的层数高。为什么层数高相对效果也更好?
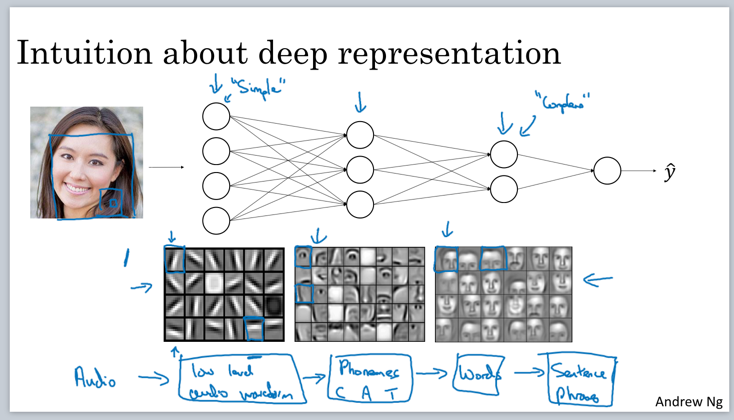
上图给出一个启发性的说明。神经网络的每个节点都可看做一个抽象信息处理单元。比如人脸识别模型,最开始节点提取「线段」信息,后面节点提取「组件信息」,最后组合起来提取「面部」信息。脑科学研究也表明,人脑的识别过程也是分层的。所以层数越多越能更好地拟合实际模型。
hyperparameters vs parameters

相比于这种直接计算的参数而言,另外需要给出假设值的参数叫做hyperparameters(超参数)。超参数决定了普通参数的最终结果。一般超参数比较依赖于经验设定,常见的方法是对不同参数结果进行评估,取其中较好的数值。