深度学习第三门课程: Structuring Machine Learning Projects的学习笔记。
ML Strategy
这里说的很多内容和之前课程中学到的内容差不多,就是如何评估你的模型,如何进行模型的比较和结果分析。
一个大的指导原则是:正交化(orthogonalization)。每次调整只影响结果的一个方面。
另外要建立评估矩阵(evaluation matrics),将相关影响的要素都列出来,但最重要的是建立one single value评价指标,该指标可以综合所有评价要素的权重。单一指标便于更直观和快速的比较出结果好坏。
dev和test集合需要分布同源。这点上文提到过,同源才可以保证目标一致。dev调整的目标和test是一样的,否则用dev优化了半天,到test发现目标错了。dev/test数据集合还需要包含可预估到未来实际应用场景的数据,这样子训练的模型才能更好地扩展到真实应用场景。
另外,模型分析中很重要的一点:评估人类的表现(human-level performance)。
先说明一个概念——模型所能达到的理论最低误差叫做Bayes (optimal) error,我们训练模型的误差不可能低于Bayes error,但却有可能低于human error。一般而言,在模型没有超过人类前,会将人类误差近似认成Bayes error来进行模型分析:

考虑猫识别问题,如果人类识别猫的误差是1%,那么8%的training error明显就比较大,两者的差值叫做「avoidable bias」。因为有7%的avoidable error,所以需要先解决bias的问题,因为我们的模型离人类的标准都还差不少。但如果hunman error是7.5%,那么虽然training eror有8%,但我们更应该优先解决variance。human error是误差分析的基准。
下图说明了消除相关误差(bias/variance)的主要方法:
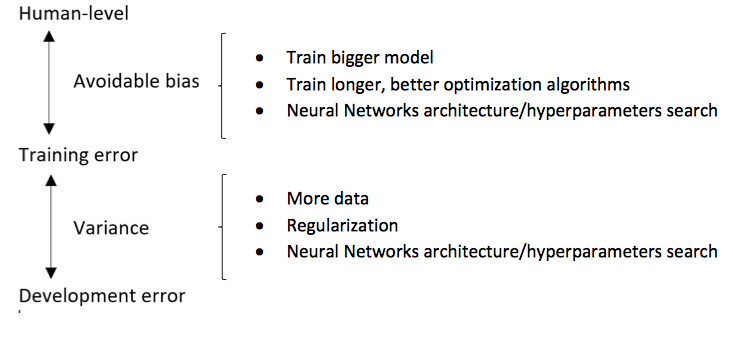
最后需要说明的是,在deep ml的一些领域(尤其是数据更加结构化的问题领域),机器学习已经超过了人类。😢
Error Analysis
错误分析的本质是要重点问题重点分析,对于NN网络而言,一个比较好的方法是对错误预估的数据进行统计:
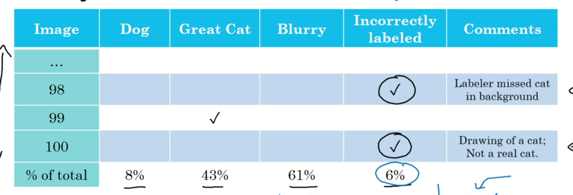
对不同种类的错误进行统计分析,优先修复比例大的问题。比如这里图像模糊会很大的影响识别效果,就可以考虑合成一些模糊图像到训练集合中。
额外说明的是,错误标识的数据是很有可能存在的。对于训练集合而言,错误标识数据如果由随机误差导致,问题不大(系统性的错误标识就有问题),可以不着急修复。而dev/test训练集合出现错误标识可以考虑处理,因为一定程度上影响了误差分析(比如和human-level进行比较)
Arrangement for dev/test set
分配dev/test集合的数据其实很有讲究。一方面我们要保证dev/test数据同源,另一方面要保证dev/test的目标有实际意义,可以更好的体现核心场景,核心数据的拟合效果。
比如考虑识别猫猫的应用,如果有200,000图片是高清网络图片,10,000是用户拍摄的模糊的噪声大的图片,应该如何分配:
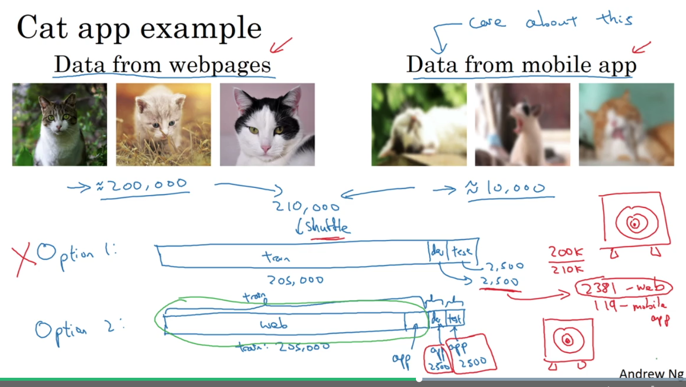
课程给出的建议是将5,000用户数据放到训练结合,另外5,000用户数据平均分到dev/test上。这样子可以保证dev/test有足够明确的目标:用户模糊图片的识别。而如果将所有数据shuffle再分配到dev/test,存在的问题是dev/test上数据很大一部分是高清数据,进而减小了拟合目标的明确性。
Data Mismatch
如果training error是1%,而dev error是10%,是不是就可以说明模型overfitting呢?
按之前的理解,看起来是的,但这需要一个前提:training和dev数据同源。如果training和dev数据分布差别很大,就不能够说明问题。使用控制变量法进行分析,从training中提取一小部分做为training-dev集合,用其来验证是否有overfitting:
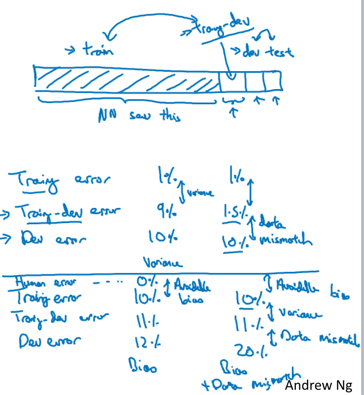
如果这时training-dev error是9%,说明没有训练的同源数据都没有拟合好,这才说明overfitting了。如果training-dev error是1.5%,那说明更多的误差是由training和dev数据不同分布导致,这个误差叫做「data mismatch」。
下图是一个更全面的分析误差的矩阵,将数据分为general和user-case两个维度,将误差分为human-level、训练到数据、没有训练到的数据三个维度:
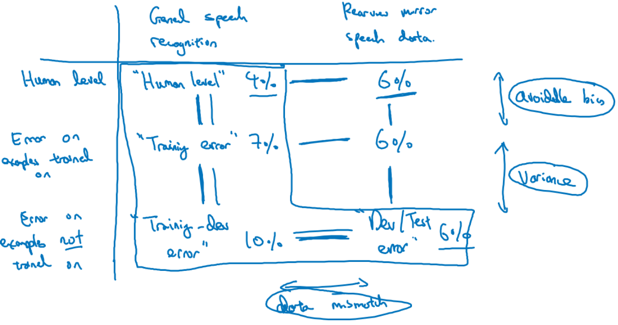
那么如何解决data-mismatch呢?没有特别系统的解决方法,但有一些策略可以参考:
- error analysis。具体问题具体分析,看看哪些点导致了问题。
- 将识别错误的用例加入到训练集合中。
- 人工合成法扩展错误用例。
比如考虑合成有噪声的语音:

课程中说,合成方法在实际工程中真的可以解决问题!但也存在一定的风险:如果噪声数据规模很小,而需要合成的数据很多,模型的训练结果可能会对噪声数据overfitting。对于人而言,用不多的噪声数据合成的结果就可欺骗耳朵,但这点上,机器却更不容易欺骗。
Learning from multiple tasks
神经网络之所以很有用,其中一个原因是因为可以迁移学习(课程中有一个视频是采访Yoshua Bengio,其中有一个问题问他为什么坚持研究神经网络?Bengio的回答是,他觉得造物逻辑一定是非常简单的公式就可以描述的,就像流体动力方程,麦克斯韦方程,正态分布,有着极其简单的形式和数学的美。AI的模型应该是足够简单且通用的,可以自我学习。从这点上看,神经网络确实是目前最体现简单和通用之概念的模型)。
迁移学习可以将一个领域的网络迁移到另外一个领域:
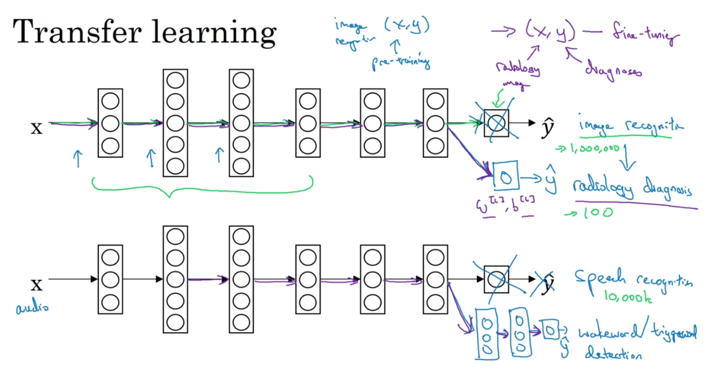
比如上图,在最后的输出环节进行「fine-tuning」,复用之前「pre-training」的模型。图中提到的例子是将识别猫的网络迁移到识别狗中;将通用语音识别迁移到trigger语音的识别中(唤醒设备「hi Siri」)
什么情况下从任务A转移到任务B是有效的:
- 任务A和B有相同的输入。
- 任务A的数据比任务B多。
- 任务A的低维度数据对学习任务B是有意义的。
另外一个维度的学习是多任务学习,一个网络同时学习多个任务:
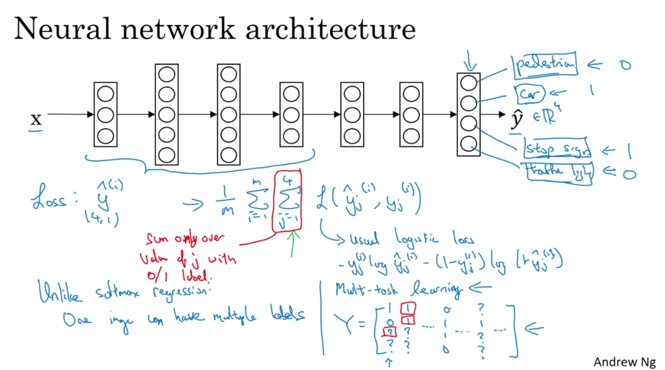
这和多类别识别不一样,多任务的输出结果中可能同时有多个1。比如上图的输出就有:是否有行人、汽车、停止标志、红绿灯。所以多任务识别不使用softmax进行最后的loss函数计算,而是直接统计所有任务的logestic数值。
什么情况下多任务学习是有效的:
- 所有训练的任务都有共性的低阶特性。
- (通常而言)每个任务的训练数据量相似。(如果有些任务数据特别多,训练可能对该任务过度拟合,进而影响了其他任务的识别)
- 需要非常大的训练网络。(多任务学习网络在足够大时,效果并不会比单独训练任务模型得到的结果差。)
End-to-end deep learning
end-to-end learning是指直接将输入和输出建立映射关系的学习,而不需要将问题分解为多个步骤。
考虑语音识别系统:在没有dl之前的研究是将语音进行特征分割,词法分析,语义分析等环节,最后对输出结果进行翻译,但实际效果反而不如直接end-to-end好:
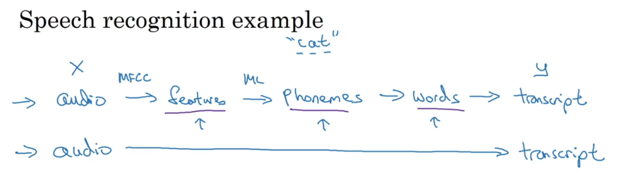
考虑另外一个引用场景,人脸识别,该问题却不是end-to-end效果更好:
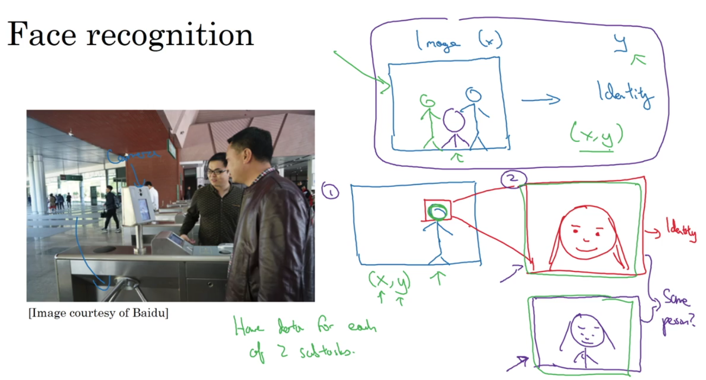
人脸识别分为两个过程:1)找到人脸 2)将人脸图片缩放,匹配人员信息。
只所以分而治之更适用于人脸识别,有几个原因:
- 每个单独的问题都有很多的数据。比如第一个问题,可以很快的利用现有数据和研究成果得到不错的结果。
- 人类领域知识体现了更明显的步骤属性。(相比于语音识别构造的理解模式,人脸识别构造的步骤更有把握)
- end-to-end的数据不多。(考虑直接从图片训练识别人员信息,需要识别人员在各种角度上凹造型,数据采集成本高)
所以,总结一下end-to-end模式的优缺点:
| Pro | Con |
|---|---|
| 数据自我表达内部逻辑。 | 更少人为设计的步骤。 |
| 需要足够多的数据才有更好效果。 | 缺少可能有用的人类领域经验知识。 |
换个角度考虑,机器学习的本质是通过数据获取知识。一种知识是无行为模式的,通过足够多的数据训练得到;另一种知识是有行为模式的,是人类经验的延伸,利用这种知识可以加速机器学习的过程。所以综合而言,关键问题是是否有足够多的数据。
其实在复杂的ml领域,都是混合使用end-to-end和hand-designing components两种模式。