深度学习第四门课程: Convolutional Neural Networks的学习笔记。
Concept of CNN
卷积操作在计算机视觉领域用的非常多,其核心是用一个大小的方块filter/kernel对图像块状区域进行加权,进而提取图像高阶特征:
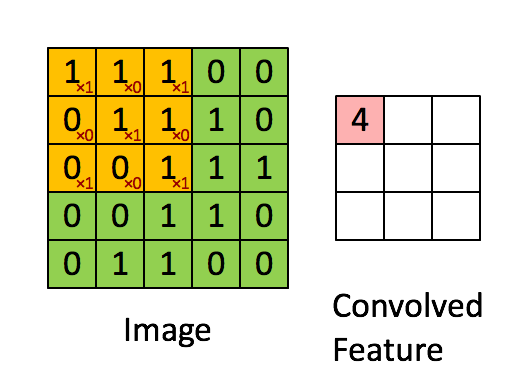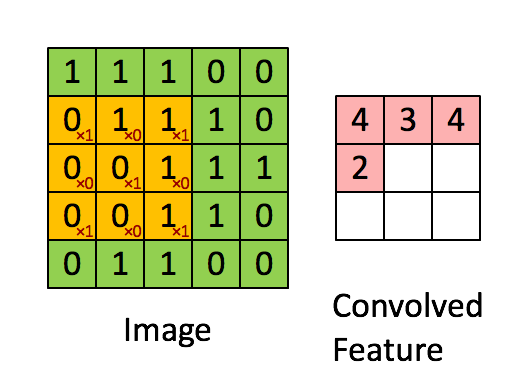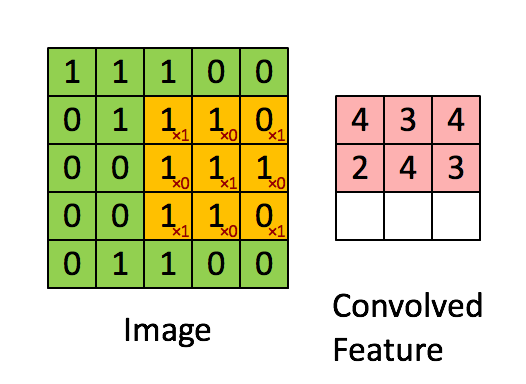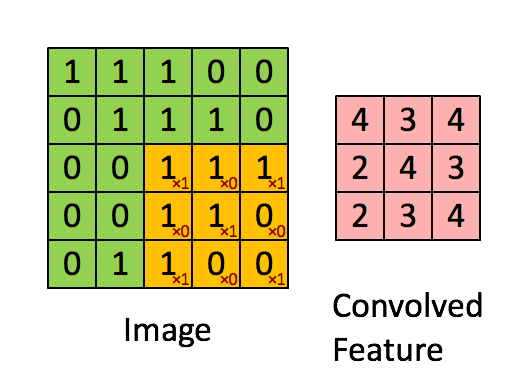
卷积操作中有一个控制参数:
- 表示卷积大小,一般是奇数
- 表示填充大小,不填充数据的话,卷积会越算越小,同时去掉了边缘信息。
- 表示每次操作移动大小,默认为1。
- 卷积操作之后的长度为
将卷积操作做为提取特征的核心操作,类比到神经网络中,就得到了卷积神经网络。
在CNN中,filter是有第三维度的,叫做channel,该channel的大小就等于上一层输入的节点数(类比于NN中第一维度是上层节点个数),然后将各个channel的filter和上一层节点数据依次运算加权统一,得到本层的一个特征。比如下图就是对原始输入矩阵(R,G,B三个通道)数据进行一次卷积操作,得到新的特征:
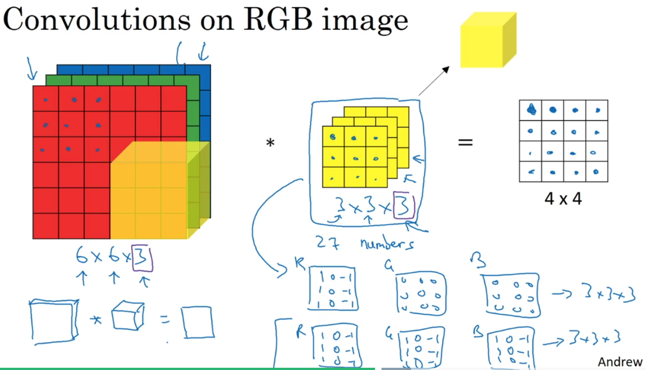
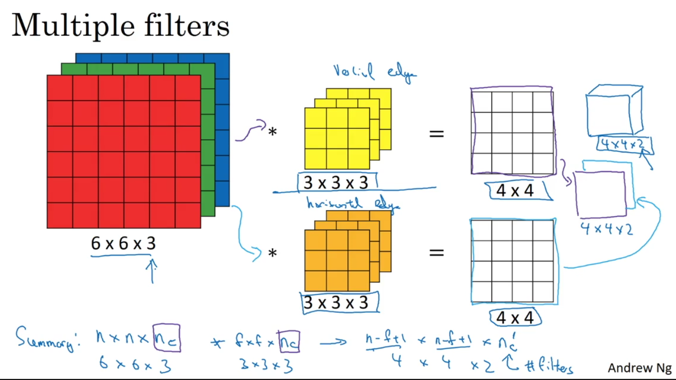
如果使用多个filter,就可以得到本层的N个特征:
其操作过程动画展示如下:
CNN中符号说明(试用了一下印象笔记的文档扫描功能,很赞):
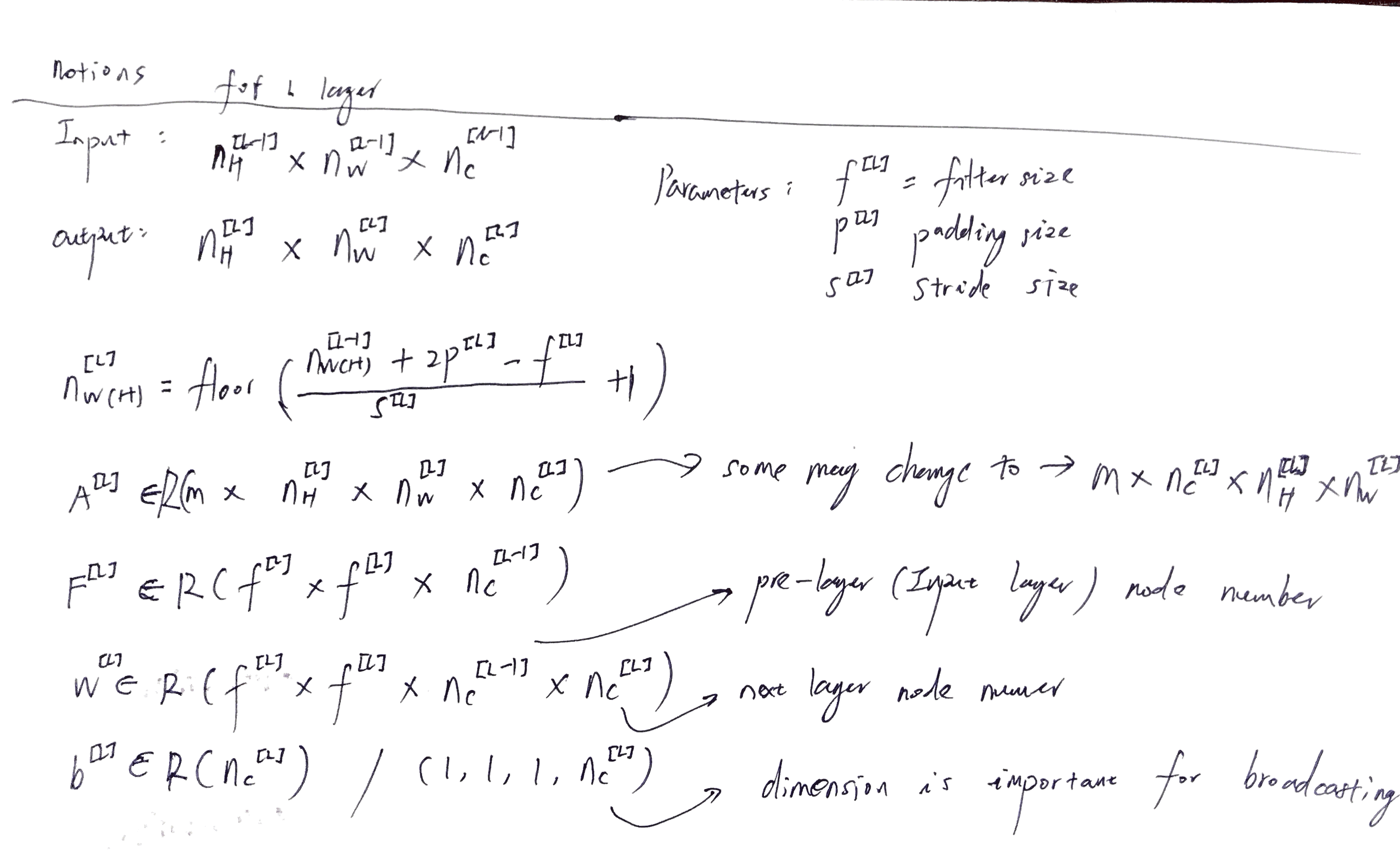
上面介绍的网络在CNN中叫做Convolutional Layer(卷积网络)。另外还有两种形式的Layer,一个叫做Pooling Layer:

Pooling Layer对每一个channel数据分别处理,提取最大值(均值,用的比较少),或者换个理解,提取最大特征,同时降维数据。所以pool layer和conv layer不一样,没有参数(只有hypterparameter,卷积用的filter/padding/stride size),同时,是对每一个channel单独处理,不改变输入数据的个数。
还有一个layer叫做Fully Connected layer(FC,在TensorFlow中叫做Dense),就是原来的神经网络模型,没有卷积运算,直接权重矩阵W进行映射,一般用在网络的最后阶段,使用softmax输出类别。
所以综合起来,一个CNN模型的例子:
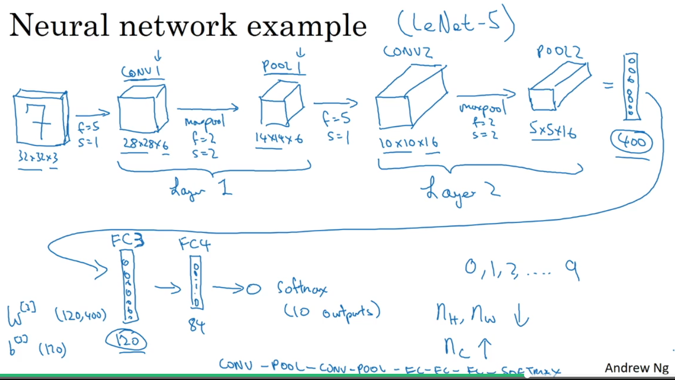
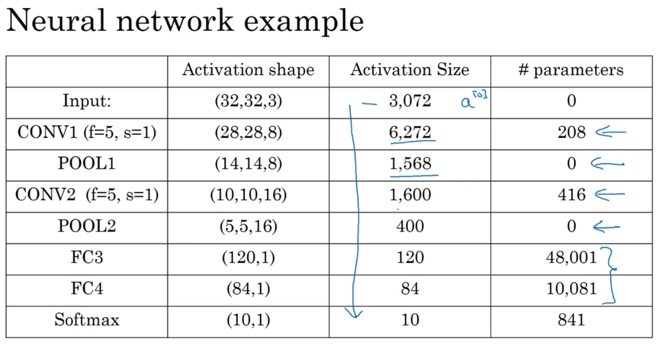
一般而言,CNN的模式是在前几层将图像维度缩小(提取更抽象信息),同时,提高特征个数(高阶特征)。
至于为啥CNN有效,课程中提到两点:1)parameter sharing,如果一个filter对图像的局部有效,可能也对全局有效 2)sparsity of connections,权重矩阵变小了很多,比NN节点之间连接矩阵小太多。
而我个人理解,可能CNN更好得模拟了大脑处理视觉的模式(个人理解):
- 大脑对图像是扫描分析的,一块一块扫描,然后得到全局信息。
- 扫描完成后,对图像的点,线,面进行拆分,组装,定位目标。
- 定位后然后识别,理解。
我理解CNN就是在模拟这个过程。最有趣的部分就是将filter变成参数求解,相比于以前的视觉算法都是手工调教参数。人脑对于模式的识别,应该是非常灵活的,目标导向且自适应的,可后期训练的。所以CNN的模式确实更像人类一些。
CNN Architecture
抽象来说,NN学习的就是知识。知识分两种:一种来自于数据,一种来自于人类经验。理论上说,在数据足够多(相对于问题的复杂程度),计算能力足够大时,最好的模型不需要人为干预,直接通过数据获得知识。但在数据不多,计算能力不够时,就需要人为干预模型来提高学习速度,提高学习效果。
VGG - 16
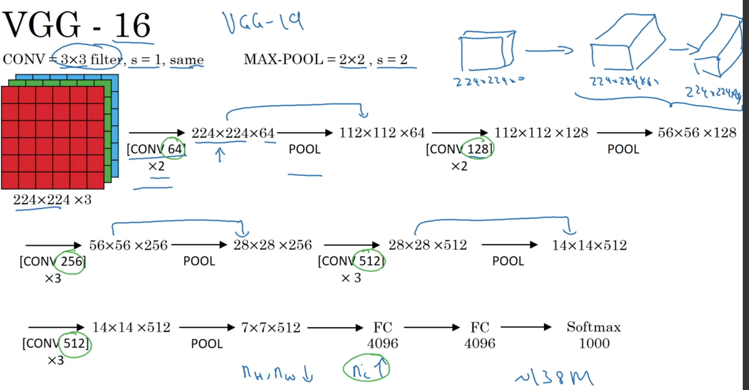
这个模型比较早,比价有意思的是,每一层计算后,图像长和宽都缩小一倍,但特征多了一倍,有非常统一的模型结构。
ResNet
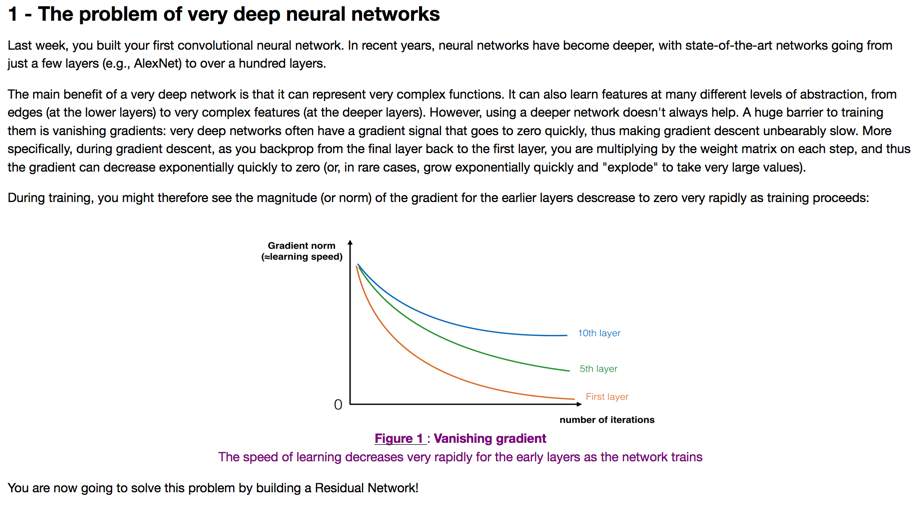
在ResNet出现之前,训练深层次网络存在一个巨大的问题:vanishing gradients。就是随着优化的迭代,权重越来越小,backprop计算时,梯度会越来越小(梯度需要乘以权重,而权重越来越小,在经过多层网络的计算后,梯度呈指数缩小),梯度缩小就会导致训练越来越慢:
ResNet核心思路是构造「skip connection」,在原有的连接基础上,构造短路(shortcut)的连接:
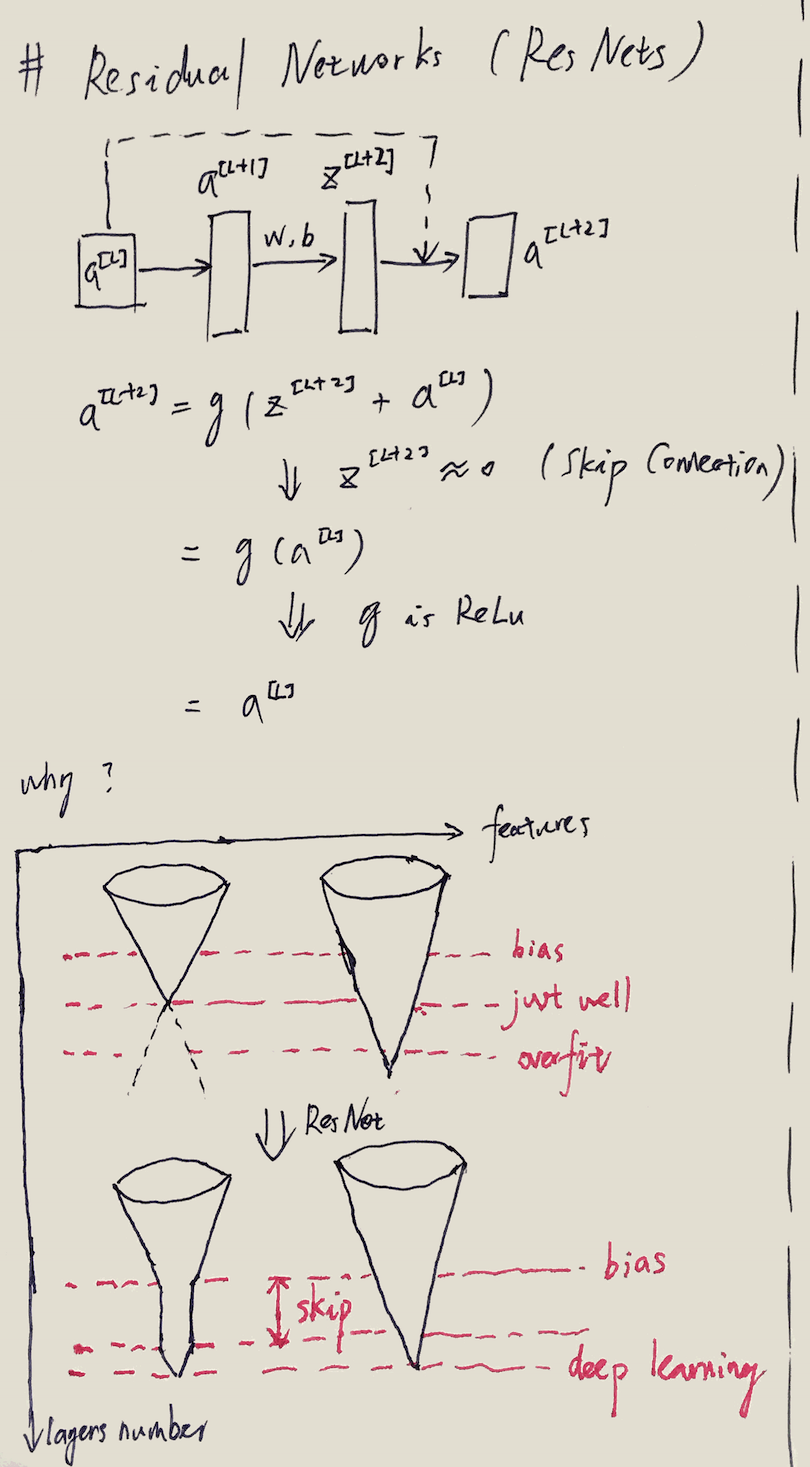
短路之后有个特性,如果中间节点的权重系数为0,那么L+2层的输出就是L层的输出,这几个网络构成了一个Identity Layer。
我个人理解ResNet可以有效工作的原因画在了上图中。特征的抽象层次肯定不会完全相同,有的特征维度高,有的维度低。如果网络特别深,会导致低维度特征还没运行到最后一层就已经最优收敛,之后再计算反而导致overfitting。但如果网络不深,高维度特征又不收敛。所以我觉得ResNet干的就是这个事情:让低纬度特征计算放缓,等着高纬度特征一起收敛。(shortcut导致中间的计算都没有用,等价于放缓速度。)
Inception network
Inception网络如其字面意思,可以自我「感知」计算,就是自动计算出hypoparameters。既然模型的filter尺寸需要人为设定,存在不确定性。那么干脆直接遍历几个常用尺寸得到的结果,都将其放到网络中计算,让系统自动「感知」。
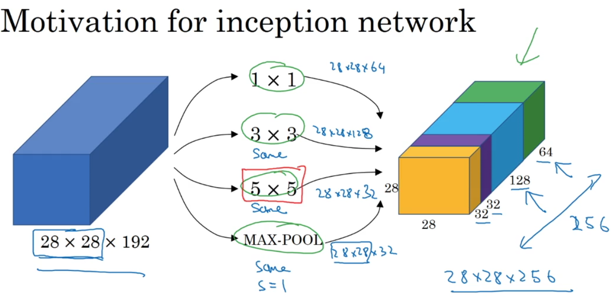
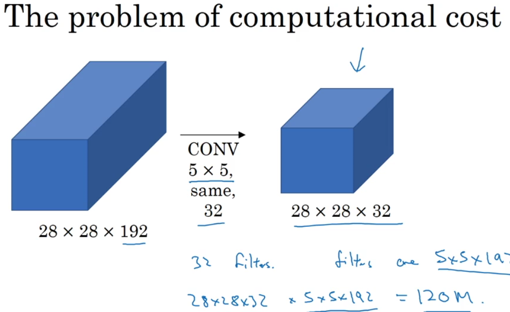
越自动,越需要数据,越需要计算量。inception用了一个方法(调整网络模型)来降低计算复杂度:
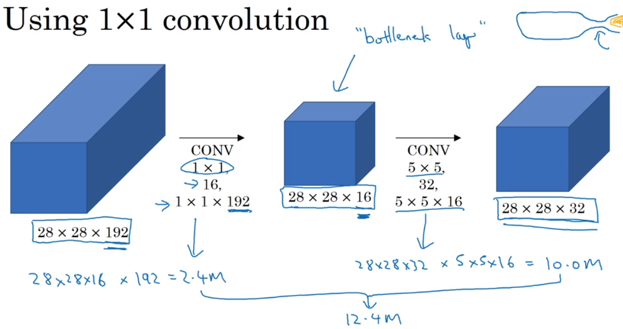
其核心就是将数据先经过一个的卷积网络,降低channel深度,然后在执行后续运算。我个人理解的卷积目的就是对原始数据进行整理,归档,将类似的数据整理归类到更小的类别中,然后降低计算量。
学完这节课,我的感受就是,这些模型用到的magical number简直就是科学的艺术,艺术的科学,神奇的1b.
更多模型框架可参考Keras Applications Doc
Detection
这节课基本就讲了一个算法:YOLO - you look only once。有些内容我也想的不是很清楚,所以先记录一下,以后觉得想的不对的,还需要进一步修正。@TODO
最开始的目标检测算法基于「滑动窗口」来扫描图像,但这存在计算量大,不确定窗口大小的问题。为此,提出了一种全卷积的扫描窗口算法:
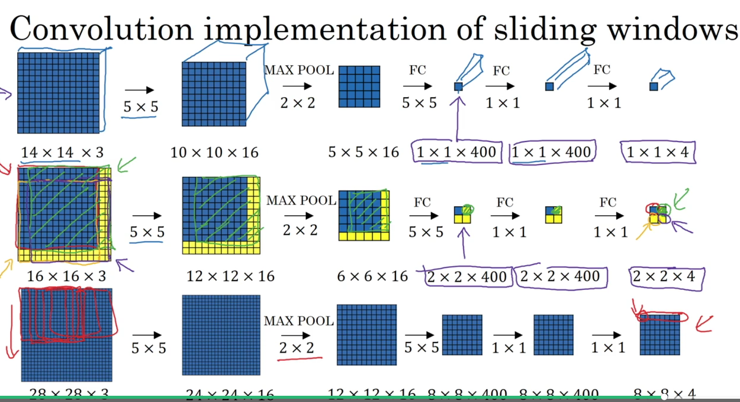
如果之前的操作是扫描一块区域图片,用操作C进行卷积运算,得到N个结果。那现在的方式是直接在原始图像上进行C操作,也可以得到N个结果,该运算和之前方式等价。我个人理解时觉得反着看运算便于理解。反着看,就会发现其实计算的映射关系是一致的。如果将卷积操作看成是将信息进行「浓缩」的数学工具,那么从全局上看,全卷积的扫描方式就是将区域信息进行了浓缩。
YOLO算法的一次扫描其实就是一次全卷积运算,将运算得到的结果分成小块,每一块等价于对原始图像一块区域的内容浓缩,然后让网络学习的内容是该小块是否存在物体中心,如果存在,标识出物体的包围盒,类别,包围盒形状
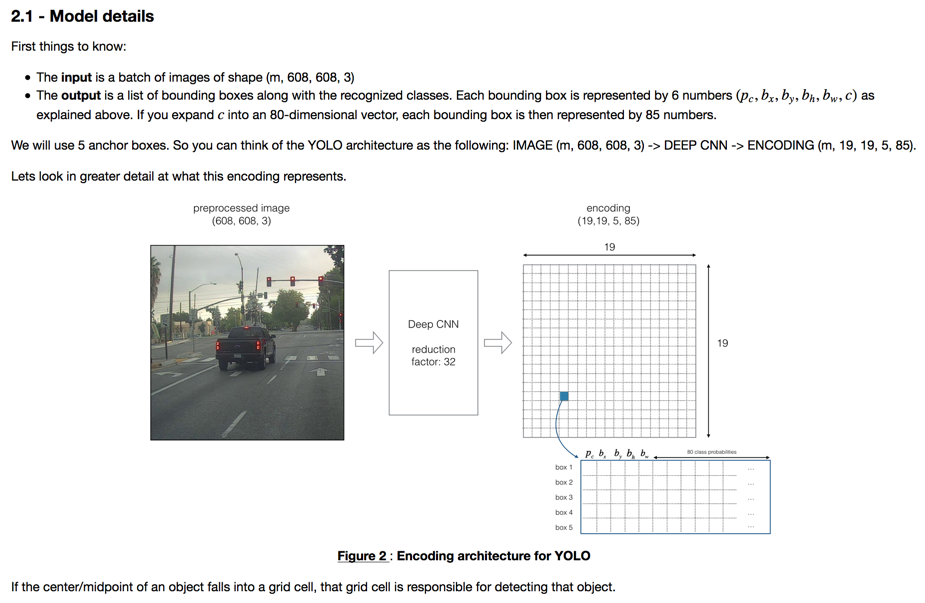
之所有有包围盒形状维度(anchor boxes),是因为可能一个小格子中检测到多个物体,所以预先对可能检测到不同形状的物体进行标定,导致输出向量多了一个维度。最多一个小格子同时检测出number of anchor boxes的包围盒。
至于优化方程,课程中没有细说,大致是对不同的数据进行区别对待。比如(probability of class)使用logestic权值,权重肯定也最高;包围盒使用均方差;类型判定使用softmax等。
系统检测出盒子之后,需要评估出哪些盒子才是有效的,这里有两个步骤:一个是去掉置信度不高的。另一个是,去掉重复的盒子。
置信度可以评估为和具体最大类别的概率的乘积:
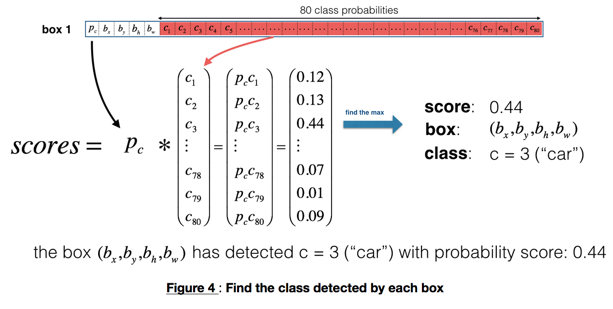
按照置信度对盒子进行颜色填充得到结果:

对盒子进行去重的算法叫做Non-max suppression,其本质是一种greedy算法:
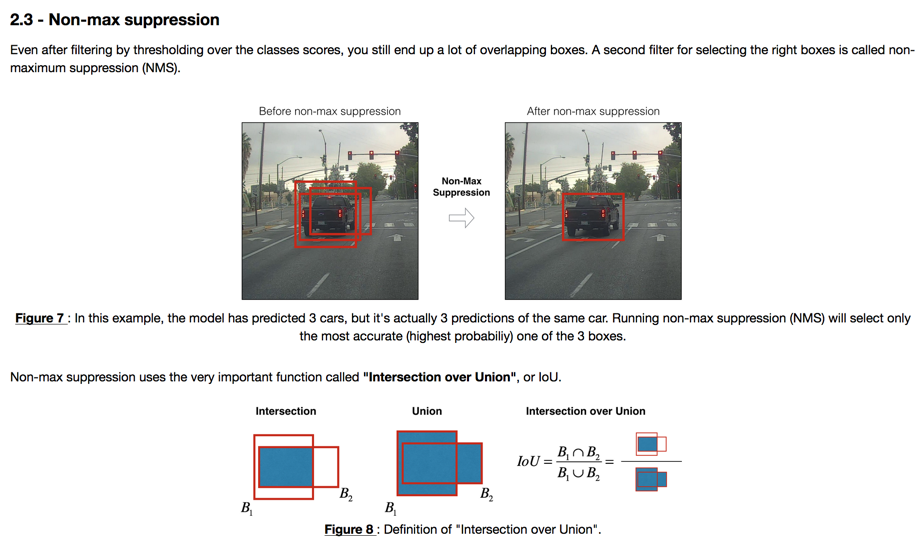
算法过程是:
- 去掉置信度不高的盒子
- 选择最大置信度盒子做为有效检测,盒子即为B
- 所有剩余盒子和B计算IOU,去掉IOU过高(一般为0.5)的盒子,表示重复判定。
- 重复2过程,直到没有盒子。
Neural Style Transfer
之前看到的网络都是训练网络参数,但网络的用法远远不止这一种,还有一种反向思维——求解输入数据。
NST就是其中一种有趣的网络:

如果从模型本质上理解,只要提供了运算逻辑,以及运算好坏的评价体系(最值得创造性扩展的建模环节),网络就可以自我求解。NST就是将生成的图片看做求解参数,并构造如下评价函数:
其中表示原始图片和生成图片内容相似程度。而表示样式图片和生成图片的样式相似程度。
CNN对图片的处理其实是在不停的提取图像的高阶特征,所以将C,G放入CNN,分别计算其高阶特征,然后求解两者相似度:

计算时,先将数据unroll,简化后续操作(将图像2D变为1D):
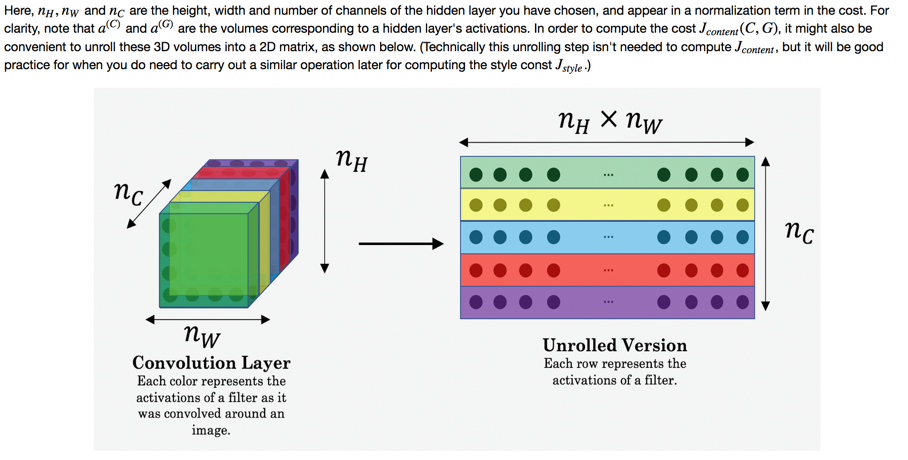
做作业时,这个操作着实让我想了好一会。最主要是考虑清楚数据的排列,如果需要将作为第一维度,需要先将原始数据按照所在维度transpose后再reshape(文字不是很好描述),贴代码:
# 将n_c放到第一维度,在reshape,后面使用-1就可以压平数据 |
style的代价计算非常有意思,简直就是艺术的数学化。在线性代数中有概念叫做「Gram matrix」,其描述了两两向量的相似度,扩展到这里:
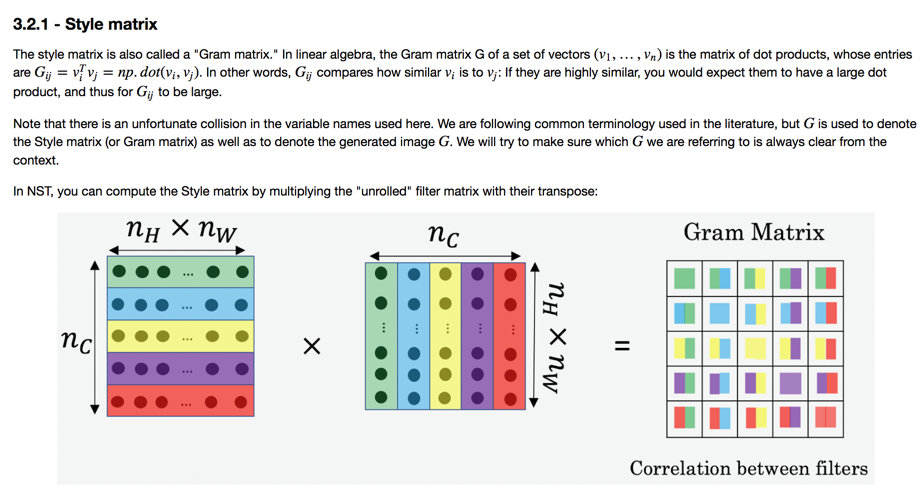
这里就知道将数据压平的好处了。将低纬公式用到多维,首先将多维压缩,然后两两相乘等价为矩阵相乘,简直是美学!换个理解,该方法就是将NN输出的特征之间的相似程度(或者是关系)作为「样式」的量化。
样式的代价就是两种代价的距离:
实际计算代价时候,会考虑多个层的输出(这点和内容不一样):
还有一个有意思的点,这里的RNN网络复用了已经训练的网络,等价于是一种transfer learning。

Face Recognition
Face Recognition和Face Varification不一样。后者是已知判定信息情况下判断是否是本人,而前者需要从K个人中选择一个。这个问题不同于K分类,因为K的数量可能非常大,而且不确定。
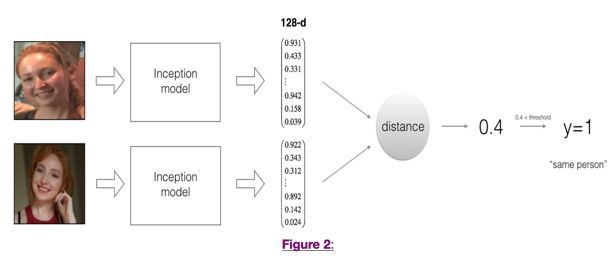
考虑另外一个模式,NN网络可以输出图像的特征,如果输出的特征可以有效的表征人脸的信息,进而进行识别,就可以让网络自己去学习。所以,模型优化的重点是NN计算的特征可以足够区别不同的人,类似于下图的特征提取:
训练的过程叫做triplet loss,每次输出3张图片:anchor、positie、negative。要求negative和anchor足够相似,这样才可以push网络训练得到更好的特征,以便分辨这些相似的人(我理解该点是该方法的核心,如果不考虑对比的因素,完全可以两两训练,没有必要三个放到一起)。其优化方程如下:

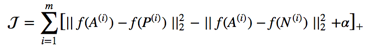
意思是让A和P之间相似程度高于A和N的相似程度,参数表示边界值,越大,网络区分阈值就越高。
识别图像的过程就是将NN的输出和已有的人员进行对比,如果满足阈值就认定匹配。NN方法之所以这样子设定,在这里也体现出优势:人员的特征信息可以pre-trained,这样子匹配就很快。
还有一种方式是匹配也加入NN训练,输入就是两个图片的特征向量,输出就是0/1的logestic regression:
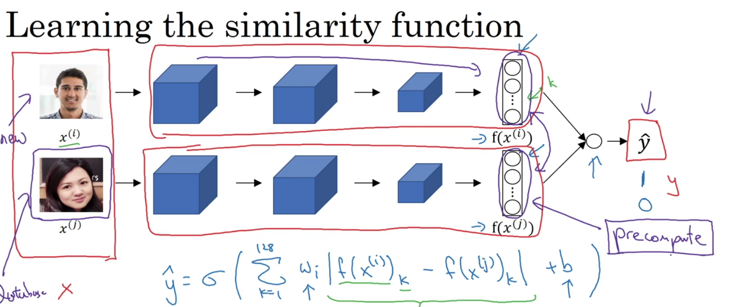
说白了,就是去掉阈值的手动调教过程,而是计算机自己去拟合。