深度学习第五门课程: Sequence Models的学习笔记。
Recurrent Neural Networks
RNN是一种处理时序数据的网络模型。考虑之前学到的网络都是一次性输入所有数据,最后得到结果。但对于时序数据而言,每次输入的数据甚至都不能一次性获得(考虑语音识别,不可能等话说完再去识别),而是连续的数据流,且数据之间有很想的时序相关性。RNN模型本身就体现了一种连续的时序概念,一个基本的RNN模型如下:
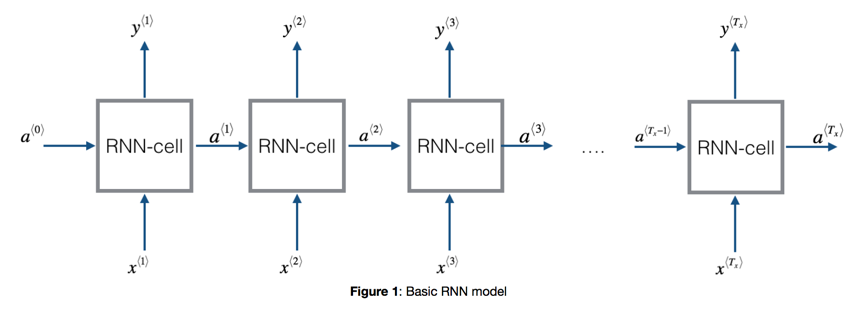
其特点:
- 数据按照时间坐标切片
- 数据按照时间顺序多次输入
- 上一层的输出结果会传递到下一层,用来拟合数据之间时序相关性。
- 每一层都可以有输出预估(根据引用场景具体会不同)
一个最基本的RNN Cell单元构造如下:
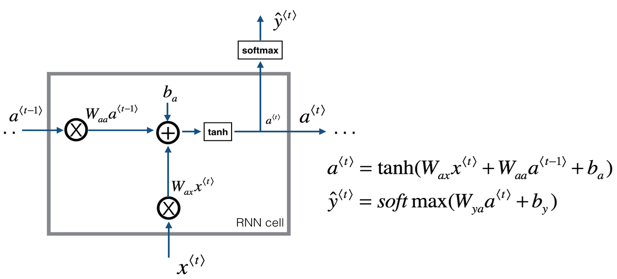
其本质就是将当前的输入和上一层的响应加权,然后计算得到本层响应和预估。(当然的输出不一定就是softmax,根据应用场景而定)
级联的RNN Cell结构如图:
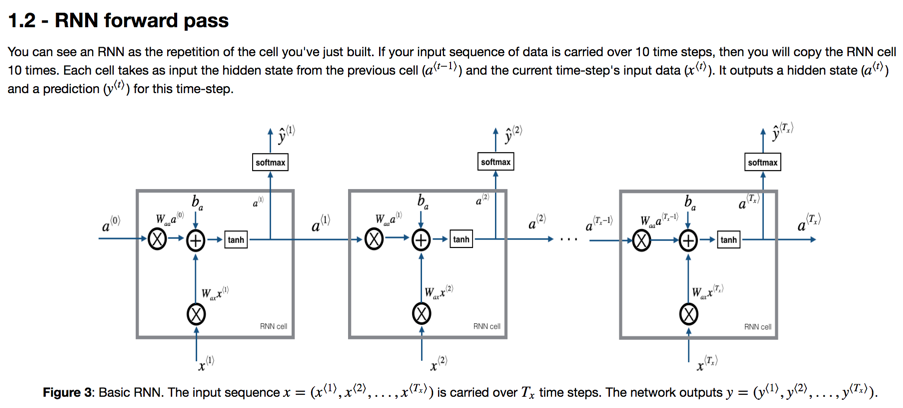
一般计算时,对时间切片进行遍历,每一次循环处理一个时刻数据和预估(因为每一次有预估就会有cost的计算),然后将数据结果cache到下一层。
基本的RNN Cell存在两个问题:
- 容易导致gradient valishing
- 时间靠后的数据很难被时间靠前的影响(层级相差很大)
时间序列的夸时间影响还是有实际意义的。比如我们说下面的句子:
The cat, which …, was … The cats, which …, were…
语义上,后面数据要受到很久之前数据的影响。Long Short-Term Memoery(LSTM) network用来解决这个问题(不是很懂,简单整理。 @TODO):
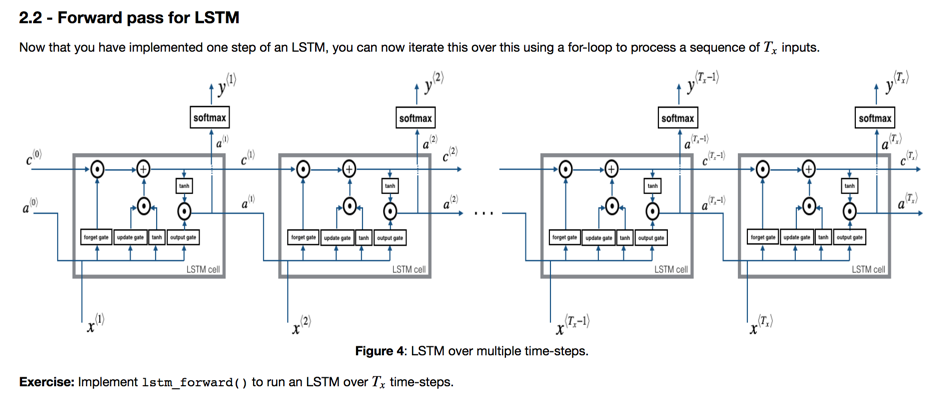
我理解本质是引入了这个通路(类似于ResNet的通路),将很久的数据按照逻辑保存下来,进而可以对后续节点产生可观的影响。
推荐一个介绍RNN非常好的博文。
Application of RNN
这里主要记录课后作业的两个项目:作曲和作文章。
计算机学习编曲其实就是让计算机建立一种乐感,这个乐感就是在听了一个key之后(当然实际建模需要考虑很多因素,比如时值,和弦等,这里简化说明),再联系之前的key list,根据概率计算出下一个key。
这里有两个过程,一个是训练,一个是Sampling。
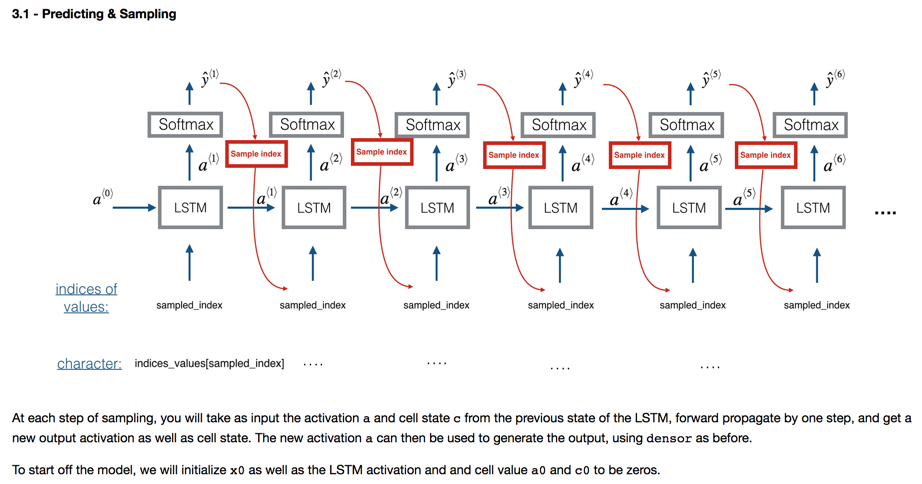
上图说明了Sampling的过程。初始输入类似于音乐中确定「调式」,然后计算机算出下一个音符(softmax的最大值,或者按照概率采样,这样子作曲更随机),然后将该音符作为下一层的输入,依次连续谱曲。interesting。
训练的过程就是反向思考上述过程,将一段音乐放入到输入位置,而每次比较的其实是错位的,也就是,最后一层的,表示结束标识。学习的目的就是在知道输入后推算出下一个输出是啥。这就是对「乐感」建模了。
贴一下生成的结果,其实听起来怪怪的,不过挺有意思:
rnn_improvise_jazz.mp3
参考项目: deepjazz keras-example: lstm_text_generation
Word Embeddings
在NLP领域,使用Word Embedding对单词语义进行建模:

上图中,单词Men可以有几个维度的解读:是否是Gender、Age、Food、Size等相关属性单词。就像是一个向量嵌入到单词的语义中,所以叫做word embedding。
其实该模型和人脸识别问题中用到的模型有些相似。人脸识别问题中,为了更好得定义人脸特性,使用CNN对人脸进行训练,得到可表示人脸信息的特征,并用triple-loss方法训练特征。这里也类似,为了更好地处理NLP问题,就需要更好地理解单词的属性,该属性就是一种特征向量。
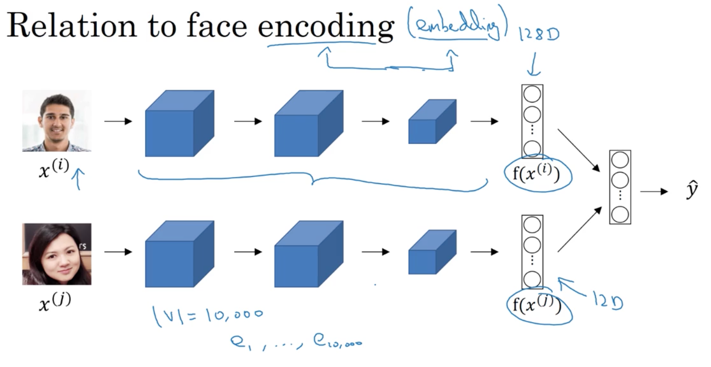
计算Word Embedding的逻辑在于找出单词之间的联系。一种方法叫做Skip-grams方法,其逻辑是提取出一个单词作为content,然后随机选取相邻单词作为target,再放到NN网络中训练:
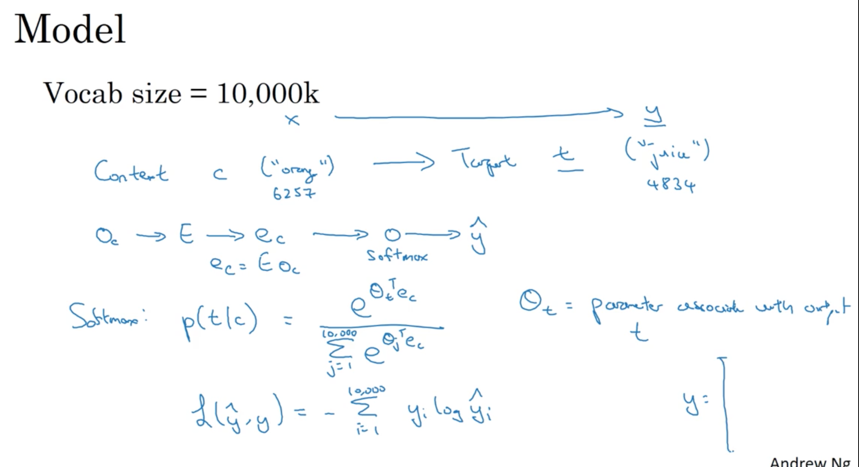
该方法存在的问题非常明显:参数居多,训练计算量太大。另一个算法叫做Negative Sampling,该算法从反面思考求解:给出content/target pair来预测是否是一个有效的关系组合。该方法类似triple-loss,将相似的有联系的放在一起进行训练:
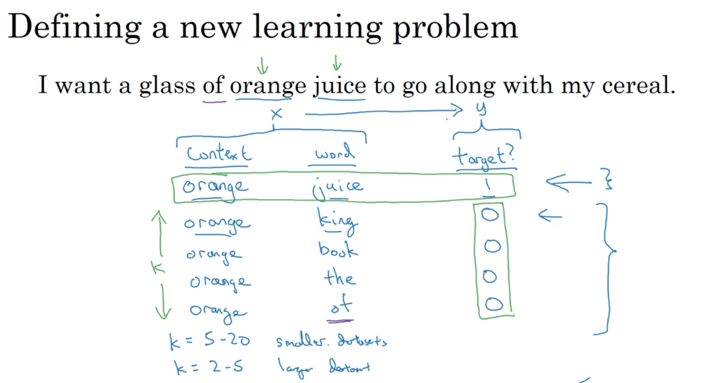
每次训练除了放入一个有效content/target训练对外,还放入K个无效的训练对。这样子问题变成了二元回归问题,计算量大大减小。另外一个方法叫做Glove方法,该方法从单词出现概率的角度进行全局分析:

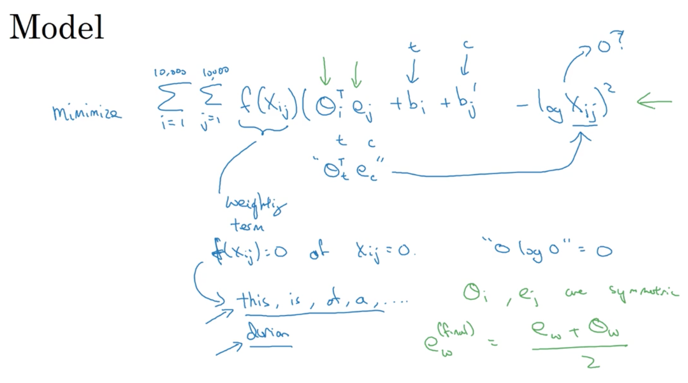
计算求解的过程就是让相互联系的单词越相似。
Word Embedding模型的一个好处是transfer learning,你完全不需要从0开始计算出特征向量,而是复用已经训练好的模型参数转移处理新的NLP领域问题。比如课程中提到的一个使用案例Sentiment Classification——根据上下文语句,判断说话人的心情:
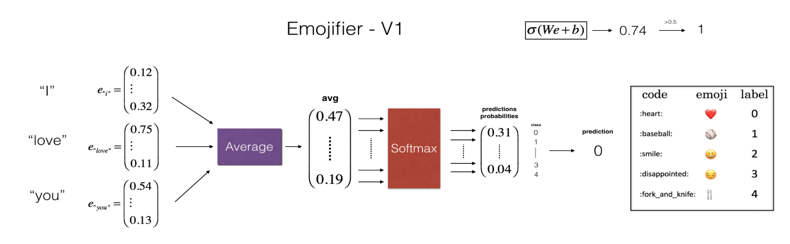
上图模型对特征进行加权放入到NN中进行回归。存在的问题时,不能理解语言的上下文,如果出现「not feeling happy」,模型还是会认为happy,这就需要理解上下文的模型LSTM:
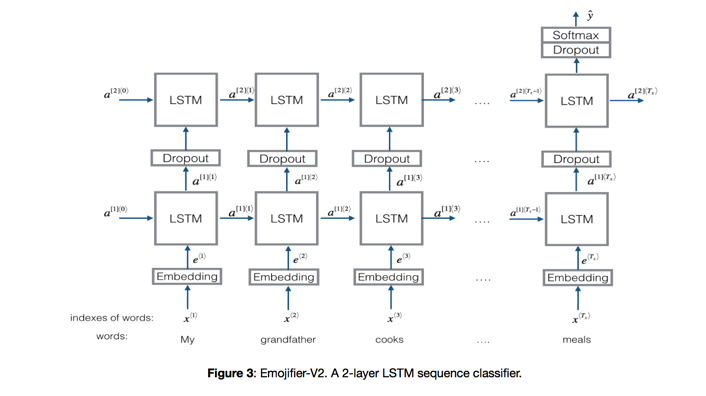
Sequence to Sequence Architectures
Sequence to Sequence的RNN标准模型定义如下:
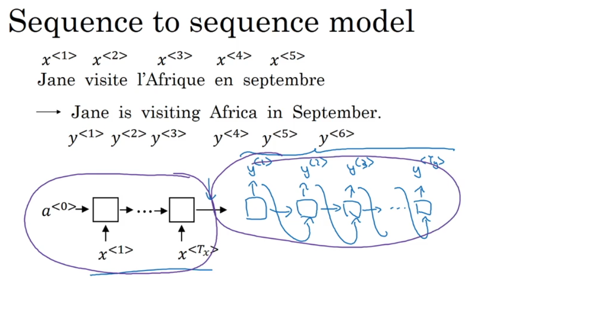
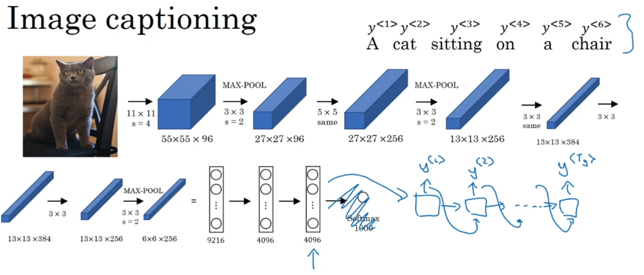
类似于之前学到的做文章问题,只是这里的输入不是0,而是已知数据综合得到的特征数据。其输入和输出都是序列数据,其应用场景有翻译和图片取标题等:
模型可以看做有两部分:encode和decode。在decode部分,算法输出的是全局最大概率的翻译结果。一种求解近似全局最优解的方法叫做Beam Search,这是一种近似最优的贪婪算法,每次只计算当前最优K个数值而不是全局最优:
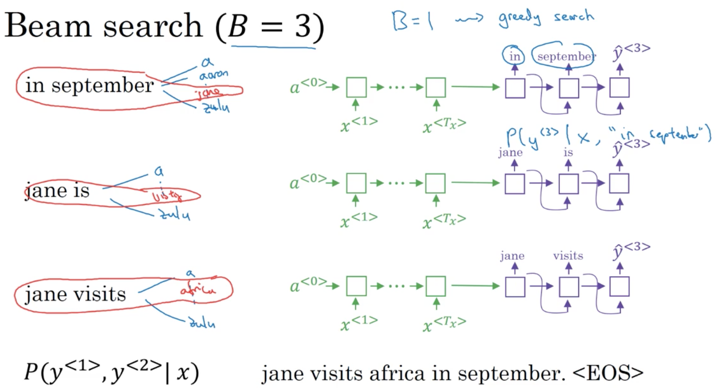

在实际计算时,如果decode的输出较深,连续相乘小于1的小数会导致结果溢出,解决方法是对数据进行log标准化。
在数据很多时,标准模型得不到好结果:
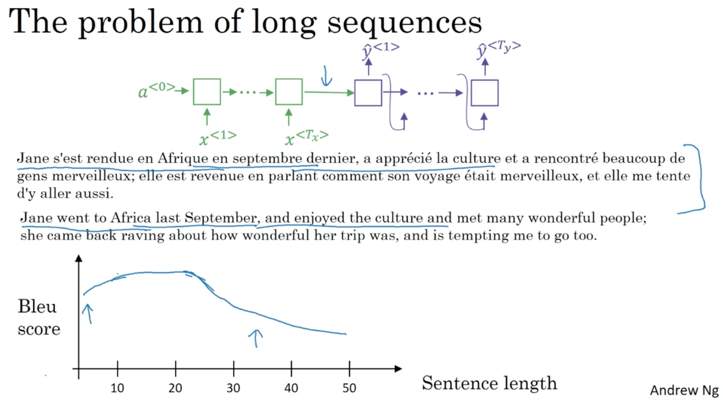
原因在于decode部分输入数据过于抽象(考虑输入是原始数据的综合,被过度简化)。而人类实际地翻译过程是每次读入一个句快,然后一块一块翻译。根据这个启发,提出了新算法Attention Model:
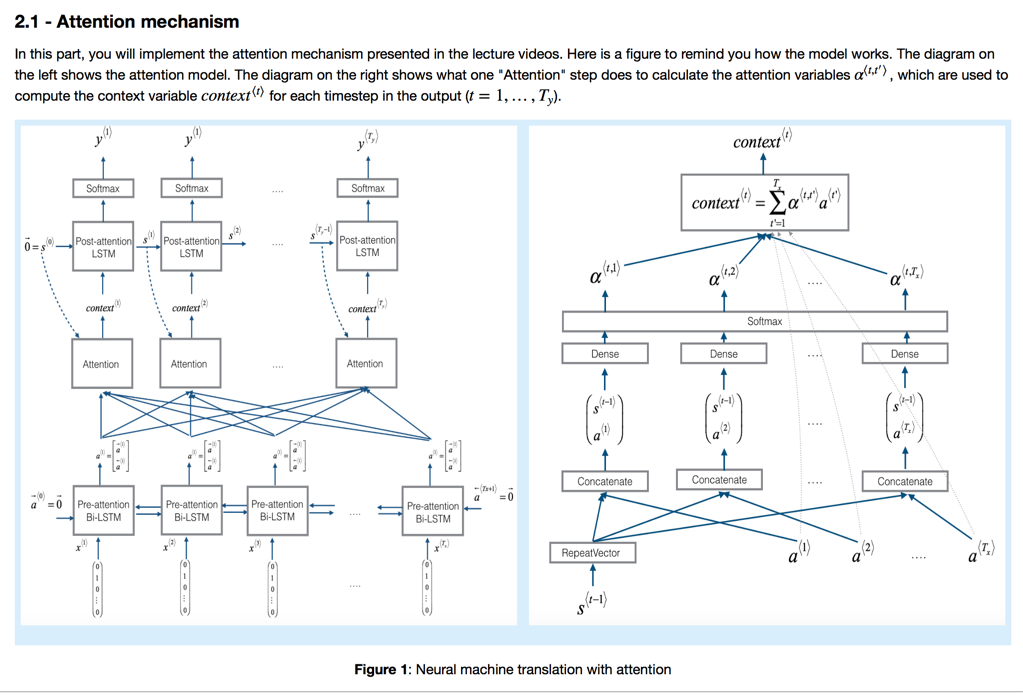
模型的核心概念attention表示每一个输出单词和当前所有输入的关系权重。权重的计算模型也是一个NN网络,输入数据为前一个输出结果和原始数据的特征(经过一层Bi-LSTM提取出来)。注意,计算attention的模型对所有t时刻数据进行计算,而不是单独计算。(权重系数也可以被理解为当前输出和输入的哪个单词最相关,进而进行类似于「直译」的处理。)
如果从模型拓扑结构上分析,主要区别在于每一次输出不仅参考前一个输出结果,也综合考虑当前加权的attention数据,起到了一种类似于人类翻译的感觉:需要不停和原始句子进行对照翻译。
课程中也简单提到了如何将Sequence to Sequence模型应用到语音识别问题上。其计算模型和上述翻译问题并不大异,最大区别在于数据建模和理解上:
- 将音频进行傅里叶变化。用频谱表征数据。
- 合理采样时间。比如以1ms为单位对输出数据进行采样,翻译的精度就可以控制到1ms。
- 理解y的输出。将翻译结果进行合并。