非常好的机器学习入门教程 Coursera - Andrew Ng - Machine Learning。记录一下我的学习笔记。
课后编程作业非常有意思:代码
课件统一整理:位置
- supervised learning(监督学习): 使用已经标注的数据计算出模型,regression/classification
- unsupervised learning(无监督学习): 使用没有具体标记信息的数据,计算机分类得到模型,cluster(聚类)
Regression
Linear Regression
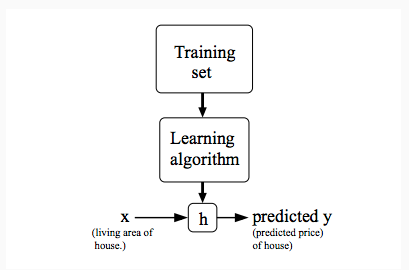
回归模型的定义如下,其中h表示hypothesis,是一个术语符号:
cost function, squared error function, 其中1/2是因而计算方便而引入(求导的时候会乘以2):
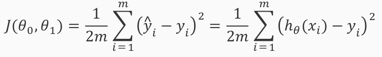
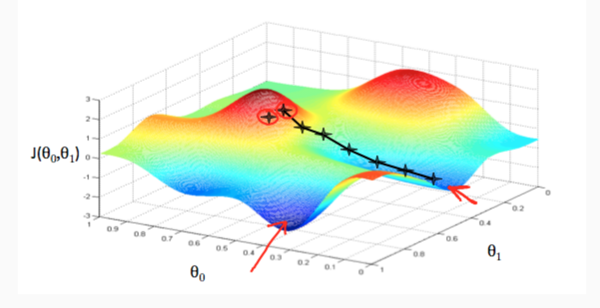
计算多元函数的最小值使用「梯度下降算法」(Gradient Descent)
算法的直观印象就是:从一个点开始,找到当前位置最好的下降方向前进一小步,然后持续迭代。
算法计算时需要同步计算,每一阶段计算数值是基于上一个阶段的计算结果:

所以代入公式可以计算得到「线性回归」方程式的梯度下降公式:
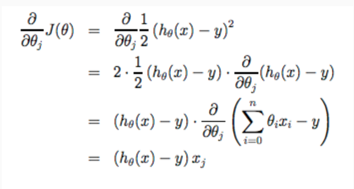
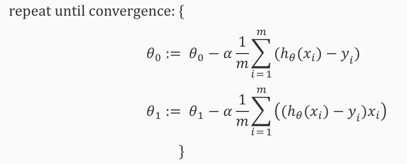
上面公式的表示数据的编号,而表示特征的编号,表示数据编号的个数,表示特征的个数(脑子中应该有一个二维矩阵了)
计算之前需要将数据进行标准化,否则,如果数据范围太不规范,会导致算法很难收敛。一种有效方式是均值标准化(mean normalization),这样子数据的均值为0,标准差为1。

实际计算过程中,需要选择合理的,如果不收敛,多数是因为太大了

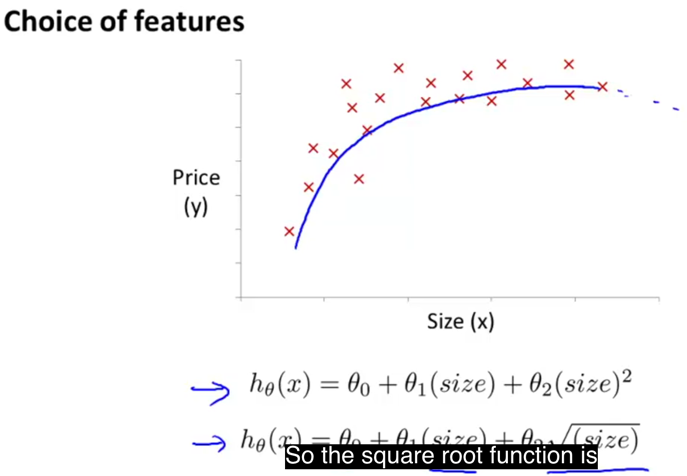
特征也可按照多项式方式进行选择(polynomial regression):
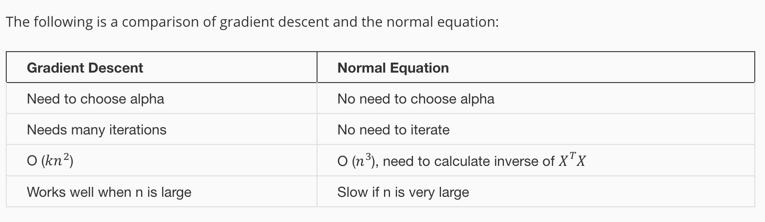
对于线性方程而言,有解析解,就是直接对求导,得到的结果是,用解析和算法解有不同的应用场景:
当然还有一种情况就是根本无法求
实际计算时,不用循环来实现代码,而是要转换为矩阵的形式,比如考虑上面的梯度计算公式,矩阵化的计算公改为:
转化的点有:
- 将求和看做矩阵相乘。
- 求和坐标就是矩阵相乘中间的维度(规约)。
- 根据矩阵维度调整顺序,比如公式中放在右边,计算矩阵时调到左边,且调为。
Logistic Regression
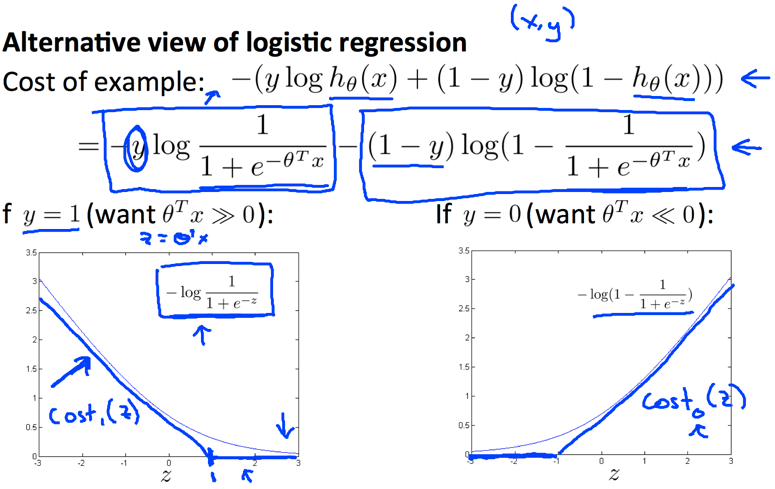
分类问题的假设函数(hypothesis)是概率函数,将原来任意数值规约到之间,所以裹了一层sigmoid/logistic函数:
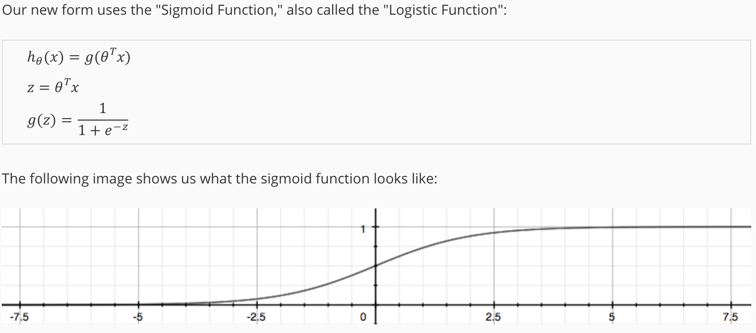
进而认定的含义是输出结果为1的概率:
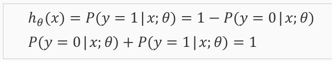
根据公式,决策的依据变成,判定的边界叫做decision boundaries,在图形上可以表示出来:

接下来考虑代价函数,肯定不能是线性拟合中的直接计算均方差的方式,因为这样子代价函数不是凸函数,不好优化计算。
考虑数据特点,,在这个基础上,如果时,如果也靠近0(注意是概率),那么代价小;反之,如果靠近1,说明分类结果是A类,但假设函数得到B类,代价要特别大。直观上特性符合log:
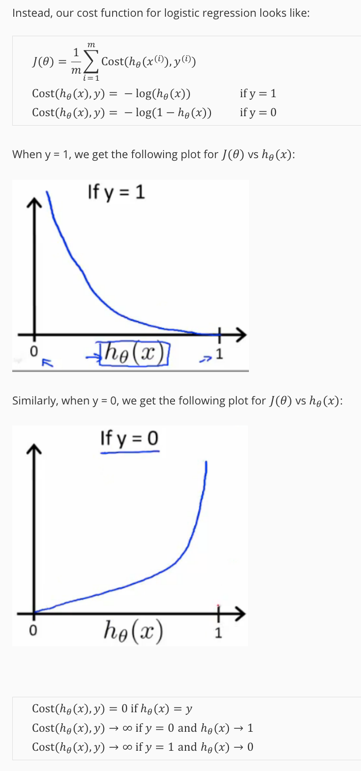
分段函数不好计算,采用融合形式:
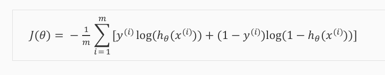
然后神奇的事情出现了,递归下降求解的数学形式和线性拟合居然一模一样,真是math magic:

拓展到多元的分类问题思路就是:将多元分类器看成N个一元分类器,然后选择概率最大的作为分类结果(数学的类比思维真重要):
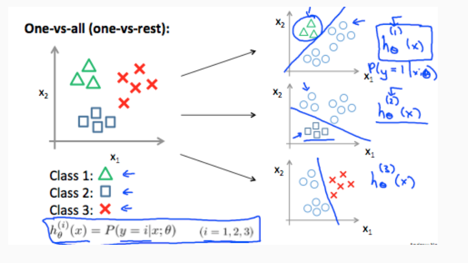
我想这也是为啥分类的算法叫做logistic regression,而不是xxx classification的原因,因为最底层的优化函数被统一了,只是hypothesis函数定位不同而已:
- 本质上都是优化问题,只是代价函数不同。
- 通过数学的方式,将分类转换为概率,然后转换为代价,进而转为优化问题。
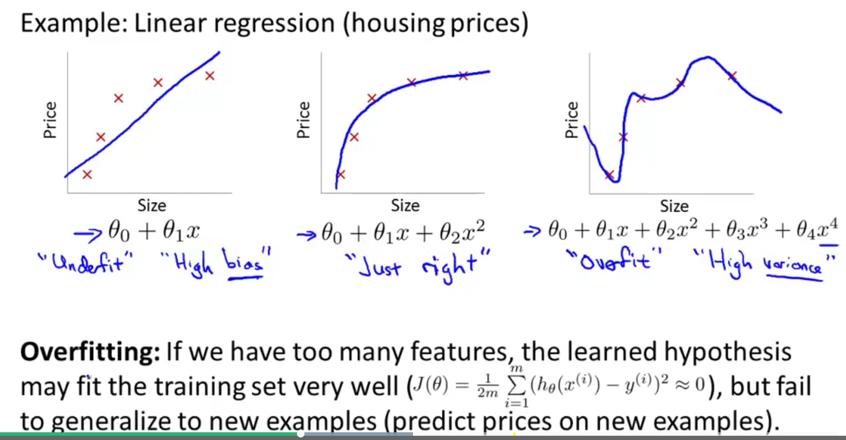
Overfitting
数据特征太多(远多于数据量),或者数据特征选择不当(高阶特征太多),就可能出现过拟合:测试集合拟合的非常好,但是预测函数并不能有效预测未知数据。
为此,提出了一个方法叫做regularization parameter:将控制参数变得尽量小,这样子不容易出现overfitting(不是很好解释,直观感受就是如果高阶特征的过大,更容易导致拟合函数overfitting):
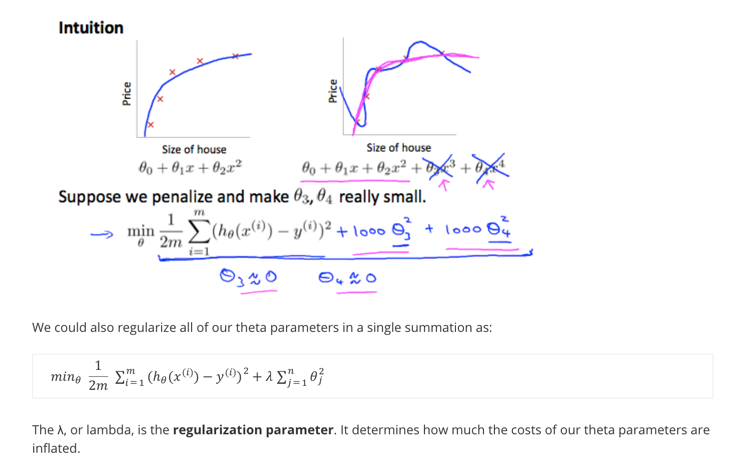
其中参数叫做规约化参数,如果过大,会使所有都被抑制到非常小,近乎于0,完全没有高阶特征,导致underfit。
代入到linear regression公式中,变成:

注意,其中的讨论有两种格式,习惯上,不对进行规则化(对实际计算结果,会有细微的差别)。
Neural Networks
考虑线性模型没有办法解决下面的问题:
- 特征太多,无法进行计算。线性模型如果考虑多阶数据,计算量成次方级数增长。
- 现实世界大多数问题不是线性。
Concept
神经网络模型模拟大脑的神经元构造方式:
- 引入层的概念。
- 每一层的数据是上一层数据传导之后的激励(activation)
- 最后一层输出结果。


其中,有几点说明:
- 中间叫做隐藏层(hidden layer), 两边叫做输入层和输出层。
- 每一层的第一个数据,叫做bias nodes
- 表示每一层的数值是上一层数据传导到新一层的结果。实际结果还需要logestic,就是
- 表示权重矩阵(weights matrix),第层的维度是,计算方式是右乘数据,且要注意0号数据的存在。
启发性的说明神经网络可以有效工作的示例:
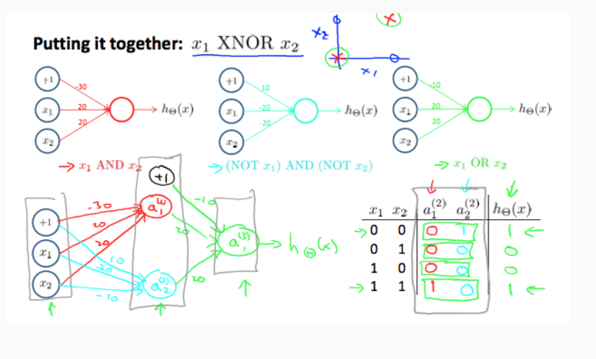
神经网络工作原理大致如此:通过不同的逻辑组合构造更加复杂的逻辑。后一层的信息是对前一层信息的再加工和升华,组合起来得到更有效信息。
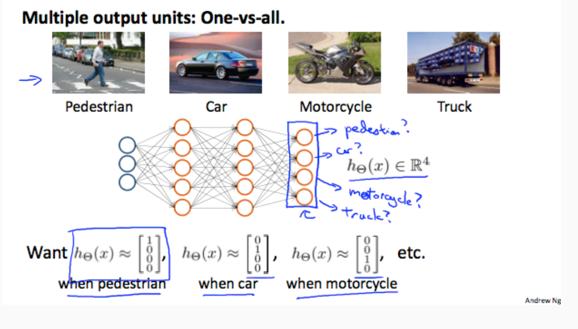
多元分类的过程就是将输出层设定为N个节点:
为了进行优化,首先需要定义代价函数——本质上是从regularized logistic regression的代价函数中延伸展开,将最终的hypothesis probablity和y加权统一,再考虑所有的权重参数:
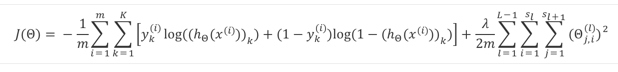
其中:

需要说明的是:规约参数的时候,不考虑bias nodes,所以计算的时候,其实际维度是.
BP
计算优化的问题核心是计算对于的偏导数,这里直接给出计算方法(想了几遍也不是完全明白,只有一个直观上的认识):
反向传播算法:
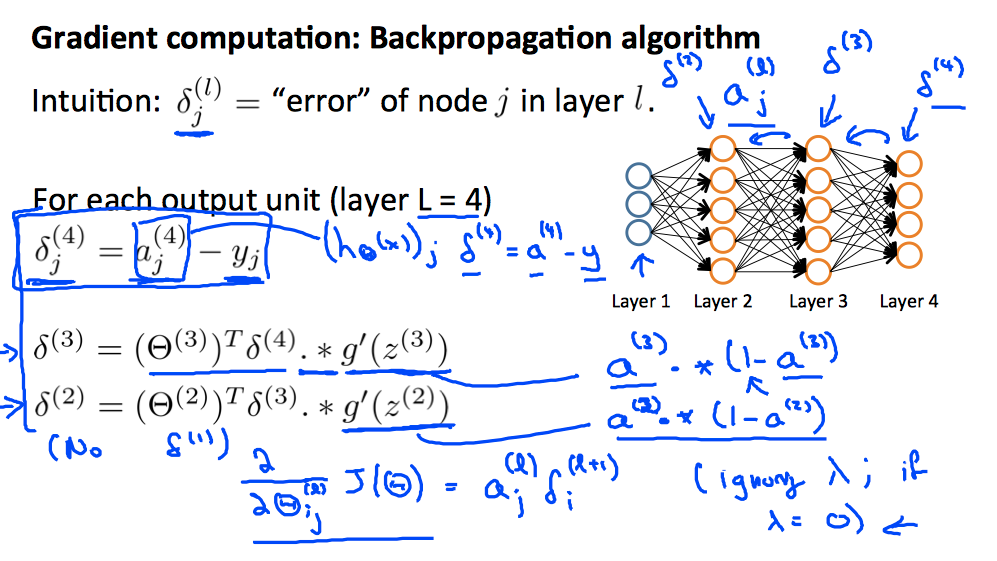

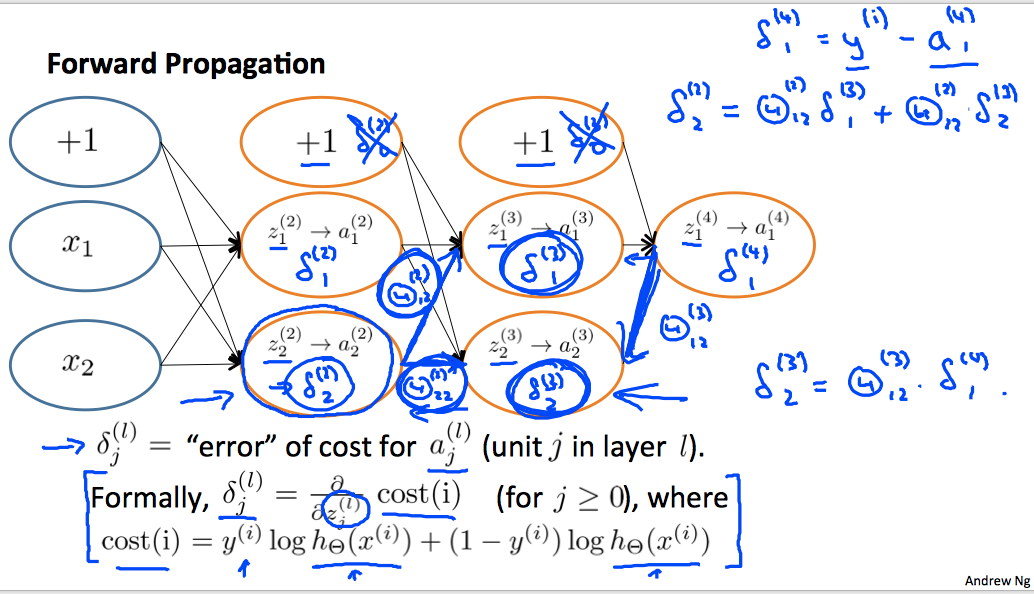
其中,主要引入了一个中间变量
- 表示第层第元素的「误差」,这个误差实际含义是第层的对第层没有logestic的求导。
- 或者换个说法,表示前一层的如何变化,第层的偏差越小。
这是一种逆向思维,如果你需要得到最后的结果最小,就必须上一层的元素符合某种优化原则,依次递归分析上去。
Implementation
实现神经网络算法的时候有一些注意点:
-
rolling/unrolling parameters
优化函数计算时,传入的参数都是列数据,而我们这里的是多个矩阵构成的大数据,所以计算的时候,需要将矩阵压缩成向量。但是计算cost的时,再将矩阵还原回来,计算代价。

-
grandient checking。
为了验证BP算法实现正确,重点是求导函数计算正确,可以用数值计算方式求导,然后验证是否计算正确。注意,实际计算BP时需要去掉验证,因为性能代价大。之所以用解析方式求导就是因为数值计算方式太耗性能。
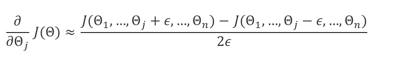
-
random initialization
初始参数不可以对称,如果对称,计算的中间结果都相同,得不到好效果。

课后作业中提到的一种比较好计算随机数范围的经验公式:
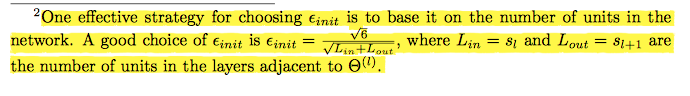
-
network architecture
隐藏层的节点个数要都一样,理论上隐藏层越多,效果越好,计算越多。
-
wrap up

not easy task.
后来我自己代码实现了一下,觉得有几个重点:
-
要经常想着维度的概念,脑子里面要知道维度是多少,然后才可以有效地计算矩阵相乘。
-
和logestic regression计算形式不一样,logestic的多元判定是计算K次结果,每一次判定的目标向量y是一个m元的向量
y == target_type。但神经网络计算时候没有多次计算,这要求每一行数据计算得到的y就是一个向量,且其中只有一个数据是1,逻辑是y = zeros(m, 1); y(target_type) = 0; -
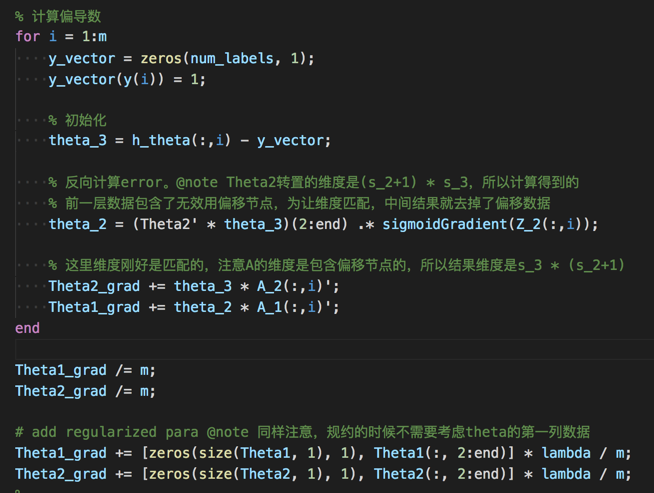
一定要小心bias node。
计算反向误差时,反向的结果考虑了bias node(正向计算输入层多一个节点,所以反向计算回来时也多一个),但这个数据并不用到,要小心。
还有就是计算regularization时不考虑bias node,也需要去掉:
Evaluating & Improve
已经实现了算法,那么如何评定一个算法是好是坏?如何确定特定的参数效果更好?如果确定了算法存在问题,应该如何改进?
课程中介绍了几种直观性的观测方法,以及对应不同情况的解决方式。
Evaluating
使用交叉验证的方式来确定最好的参数,然后使用测试集合来确定模型的好坏:

为什么不直接使用test测试集验证参数,并且评估好坏呢?
如果只有两个集合,那么test测试集合得到的参数只是在当前所有情况中找到最好的参数,但是并不能说明对于未知数据评估的好坏,直观理解上有点矮子里挑将军的味道,就是可能训练集合算出的参数都不好,但是还是在不好的参数堆中选了一个最好的,这并不能说明训练模型的好坏。
Bias vs Variance
上面就说到了,过大的偏差对应underfit,过大的方差对应overfit。
通过交叉验证的结果可以大致判断当前模型是underfit还是overfit:
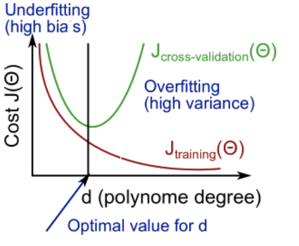
随着训练特征参数维度的提高,训练误差是会减少的,但是不代表可以预测数据,这就要看交叉验证训练集的误差。
- 当 和都很高,且数值接近时,underfit。这时候你训练的结果既不能拟合数据,也不能预测未知数据。
- 当很小,但 很大,且远大于的时候,overfit。这时候你训练的结果可以拟合数据,但不能预测未知数据。
换另外一个形式的解读:对于regularization的参数进行遍历交叉验证,可以得到大致图形:
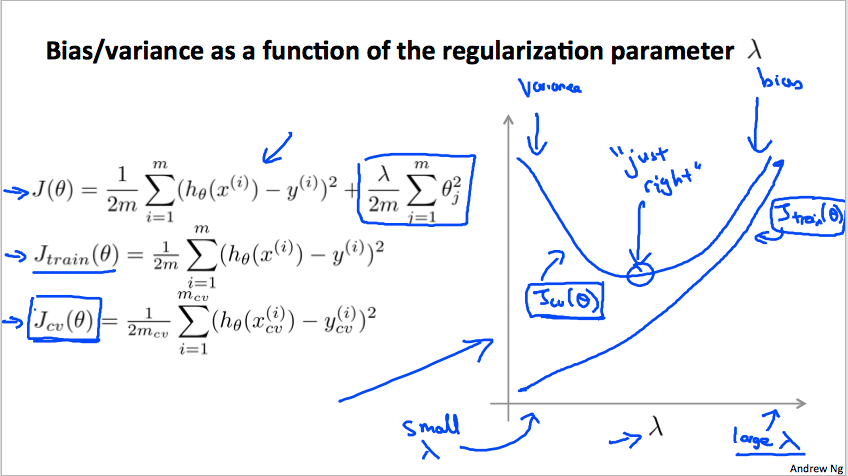
可以看到随着的增大,高阶特性抑制越大,容易underfit,相反,容易overfit,从图中可以清晰看到大致情况。
另外一种判断当前拟合信息的方式是对训练集合的个数进行交叉验证,画出来的图形叫做Learning Curves。
两种情况:


总结就是:
- 如果underfit,两个集合的误差都很大,数值也接近,数据越多并不能得到更好效果(因为压根没有办法拟合)
- 如果overfit,两个集合的误差间隔较大,数据越多,效果会越好(因为高阶特性能更好的得到整体考虑,进而拟合出更好的模型。)
所以,总结一下,面对问题的解决方法:
| method | fix |
|---|---|
| Get more training examples | fix overfit |
| Try smaller sets of features | fix overfit |
| Try get addional features | fix underfit |
| Try adding polynomial features | fix underfit |
| Try increase | fix overfit |
| Try decrease | fix underfit |
为此,课程中推荐的解决machine learning问题的步骤是:

注意,使用cross validation集合来分析问题,而不是test集合。因为如果使用test集合来分析问题,调整模型,就等于有意识的迎合测试集合的特性,而用cv集合来分析调整模型,最后得到的结果再用test集合进行测试更有意义。
关于数据和特征的选择顺序:
- 选择足够多的特征(logestic/linear regression),或者神经网络使用足够多的hidden units(神经网络的隐藏层就是在扩充特征的数目,而且是非线性特征),这样子可以保证low bias
- 然后使用足够多的数据,可以保证low variance
Skewed Data
如果数据标记结果大多数都是0或1,比如考虑cancer问题,大多数结果都是非cancel,这种数据叫做skewed data。
存在问题是:可能cv验证得到误差非常小,比如5%错误率,但实际上计算结果并不好。考虑到数据中可能只有0.5%数据是cancer,预测模型非常容易就将数据都预测为非cancer,虽然误差只有5%,但可能所有的cancer的病理都被判定为没有cancer,所以并不准确。
引入precision/recall的概念

- 习惯上,将标记为不太容易出现的类别标识。(anomaly)
- precision表示预测出来为1的结果中有多少是真的1。换个理解,如果precision高,表示预测结果准确,预测出来为1的结果非常可信,因为大多数都是真的1的样例。
- recall表示标记数据集合中是1的数据有多少被预测正确。换个理解,如果recall高,表示标记集合中为1的数据基本都被预测到了,模型非常容易将数据判定为1,但可能准确度不高(太容易放行)
换一个角度来分析一下,对于二元判定问题,设定不同的阈值对precision/recall的影响:

- 如果希望预测的结果非常可信,设定的阈值比较高,导致precision高,但是recall低。基本上预测出来是癌症的多数是癌症,而不是让不太可能的情况预测为癌症,让病人心里难受。
- 相反,希望预测结果可以反映大多数可能是癌症的情况,让病人可后续跟进治疗,设定低阈值,导致precision低(放行太多),但是recall高。我想这也是recall的来源吧,表示还需要进一步去recall查询下,看是不是真有癌症。
一种自动计算阈值的方法是结合考虑precision/recall:
这样子,如果任一个数值如果是0,价值将非常低,两者都比较高的情况下,价值高。这是ml领域常用的一种计算方法。
SVM
Concept
自己学的时候也不是特别的明白,所以这里总结一下明白的内容,不一样完全正确,有待以后理解之后重新修订。@TODO
SVM是一种logestic regression的变种,其第一个改动在于如何计算预测的结果和标记结果之间的代价。在logestic中,代价使用log关系来表述,函数连续,概念上定义为特定种类的概率,而SVM不使用连续函数,而是将数值截断:
注意图中的横坐标是,是没使用logestic规约前的数据,换个理解就是:当的时候,如果数值大于1,就没有代价,可以理解为logestic连续函数的一种降维解析。课程中描述这样子可以计算的更快,考虑到变成了非连续函数形式,就不能使用偏微分解析解计算梯度,所以可能的实现方式是使用高度优化的数值计算算法计算梯度,可能这也是SVM设计出发点之一。
优化的方程变为:

注意描述形式:
- 参数去掉了的计算,等价于原来的,所以越大,越容易overfit.
- 另外,我想不计算的原因(相比于logestic)是因为计算的代价不具备规约性。logestic的计算结果是概率规约到log函数的输出,是连续的,数据可能很小,也可能很大,所以需要进行规约,否则不同规模的代价结果会完全不一样,没有可比性(不规约的话,基本上数据越多,最终的代价越大)。而这里是断层的函数,不是连续的结果,而是大是大非的结果,所以结果和规模没有关系,也就是不同规模的也可以比较(相反,如果规约,可能数据越多,代价越小。试想,大多数单个数据代价是0,有几个数据代价比较大,结果一规约,代价被平均了)。
SVM也叫做large margin classification,因为其计算得到的决策边界距离数据集的边界都比较大。其实也好理解,如果划分有偏向性,或者说距离特定类别数据更近,那么另一侧数据导致的代价就会较大:
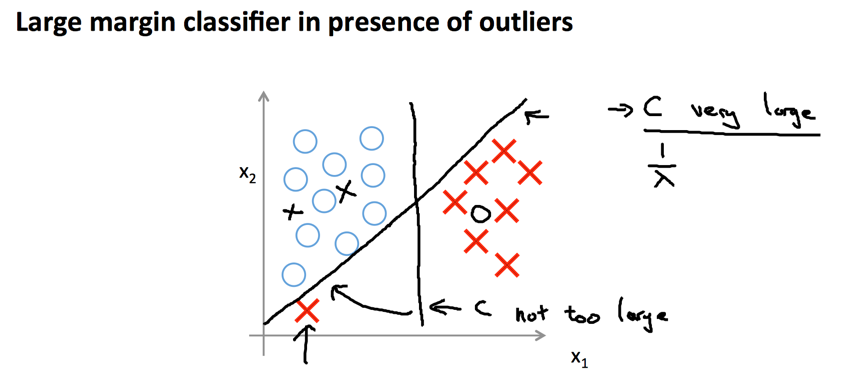
参数越大,划分的边界距离会变小,因为需要更多的考虑突出的节点导致的cost急剧变大,也就会更好的迎合所有节点,进而导致可能overfit。
Kernel
SVM的另外一种形式是Non-linear,也就是特征数据组合出了非线性特征(类似于NN算法的隐含层),其核心就是引入了kernel概念。
kernel的目的是将特征集合映射到另外特征集合,这样就等于将特征数据进行了非线性化扩展。常用的kernel是Gaussian kernel:
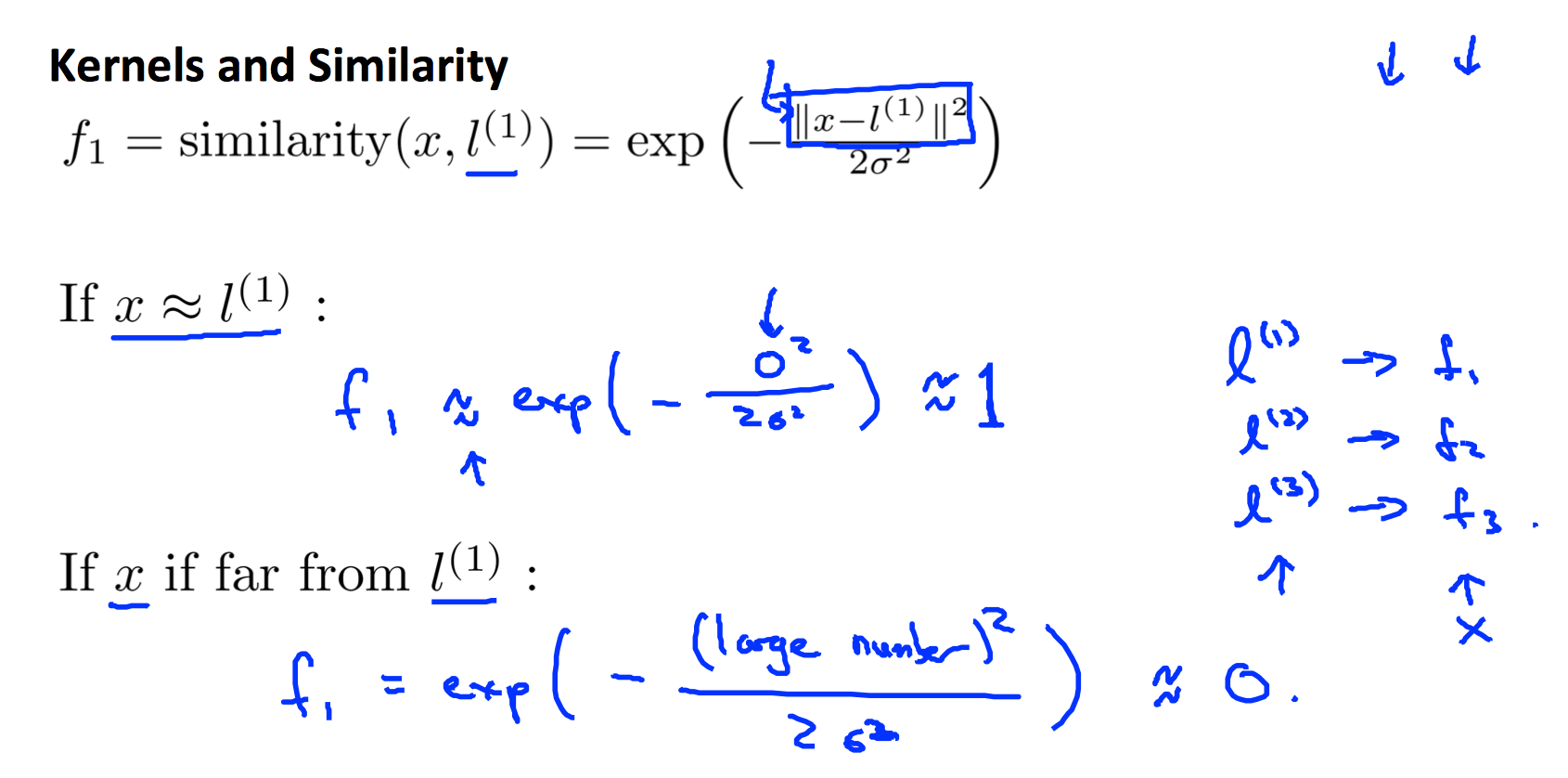
其中,表示标记数据。高斯kernel的意义就是将特征集合和所有标记数据的相似度作为新特征。一般将标记点设为数据集合本身,这样子每一个数据都和个其余数据计算相似度,最后得到。
上述构造过程的一个启发式理解:
- 当很大,而很小时,可能出现underfit,所以需要更多特征。
- 可以挖掘特征的地方就是已知的特征本身,因此我们要充分利用特征的相关性来构造新特征,也就是要将单个特征和全局特征联系起来考虑。
- 所以想到每一个数据和其余个数据进行比较,使用相似度的方式将类似的数据集合更好的归类到一起,进而加权影响到最后的权重。(如果我们越相似,且结果也类似,那么集聚起来就成了趋势)
Gussian Kernel的图形类似一个帽子:
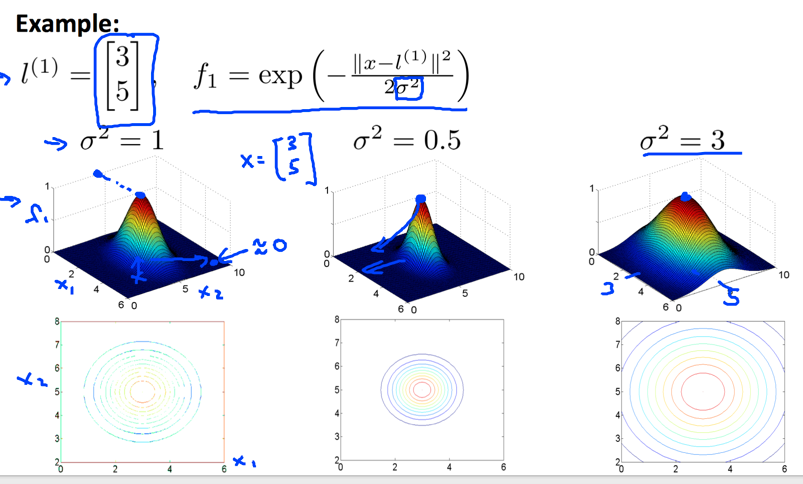
如果数据完全一致,结果为1,否则,距离越远,相似度越小。参数表示偏差大小,数值越小,帽子越尖,要求越苛刻。
偏差对模型的影响和参数刚好相反,如果越小,说明要求越苛刻,必须比较接近才算相似,需要更好的拟合训练数据,也就会容易出现high variance。相反,越大,要求越松,拟合要求不那么高,可能出现high bias.
特别提醒,计算Gussian kernel之前要将所有数据scaling,否则不在维度的各个特征之间加和计算的相似度没有意义。
修改后的SVM优化方程变为:

没有使用kernel的SVM也叫做使用了linear kernel == no kernel。
Logestic regression vs. SVMs

总的说来:
- SVM使用kernel的版本是非线性模型。
- 特征数量相比于数据数量更小时,使用SVM扩展特征更好。
- 数据特别多时候,SVM计算会比较耗时,可以考虑加入更多特征,使用logestic。
- 总的说来,SVM应用场景更多,因为一般数据都没有那么多,但相比于特征又显得较多。
K mean
之前讨论的都是监督学习算法,现在讨论无监督学习算法,首先讨论的是聚类算法。在没有标签数据的情况下,如何将数据进行聚类。
K mean算法的优化方程是:

其目的就是找到K个类别的中心点,使得每一个数据和其对应类别的中心点距离之和最小,也就是有最好的全局内聚特性。
迭代算法:

过程上有两个步骤:
- 在确定的情况下,计算出,也就是对应数据的类别。这个其实很容易理解,数据的类别就是距离最近的中心点标号。
- 在确定情况下,也就是每个数据的判定类别确定情况下,推出使得代价最小的。这个也好理解,分类好数据的最小加和距离中心点就是几何中心。
- 之所以迭代算法可以解决该优化问题,是因为两个需要优化的参数存在相关性。都是在已知A的情况下明确的知道最好的B在哪里。
初始的中心点选择很关键,选择的情况不同会导致不同的聚类结果(local optimization)。一般操作方式是:
- 从数据中随机选择初始点(更能体验聚类的内耦合特性)
- 多次执行,取最小的初始点集合。
另外一个问题是如何选择有效的,一般而言,没有特别好的方法,主要是靠人工的方式分析,根据数据的特征,需求的特征来判定。一种启发性的方法是分析和的关系:
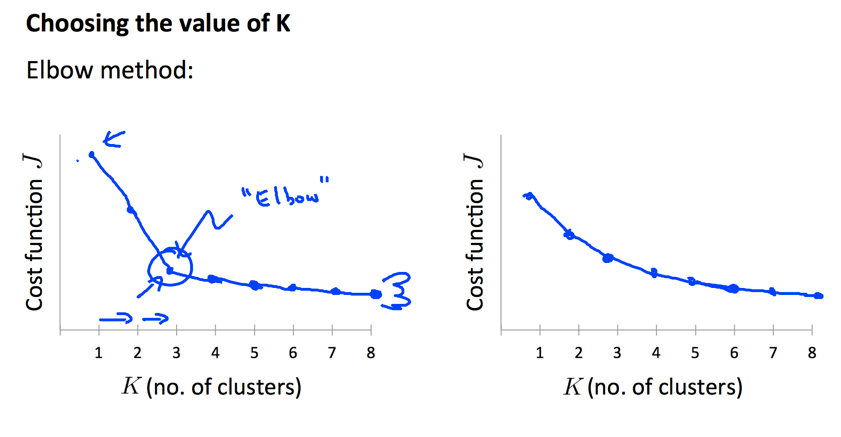
如果出现明显的碗装分割点,可以选择,否则,还是要靠人为的分析。
PCA
PCA主要目的在于数据降维:一方面降低了数据计算量,二方面可以用来可视化分析。试想,如果将数据压缩到2D或者3D,就可以直接画图来分析数据特性,更好地理解数据。
PCA的核心思想是将维数据映射到维,使得原始数据到映射平面的距离最小,这样子映射数据可以更好地反映原始数据。经过数学推导,其本质是计算原始数据集协方差矩阵的特征向量:
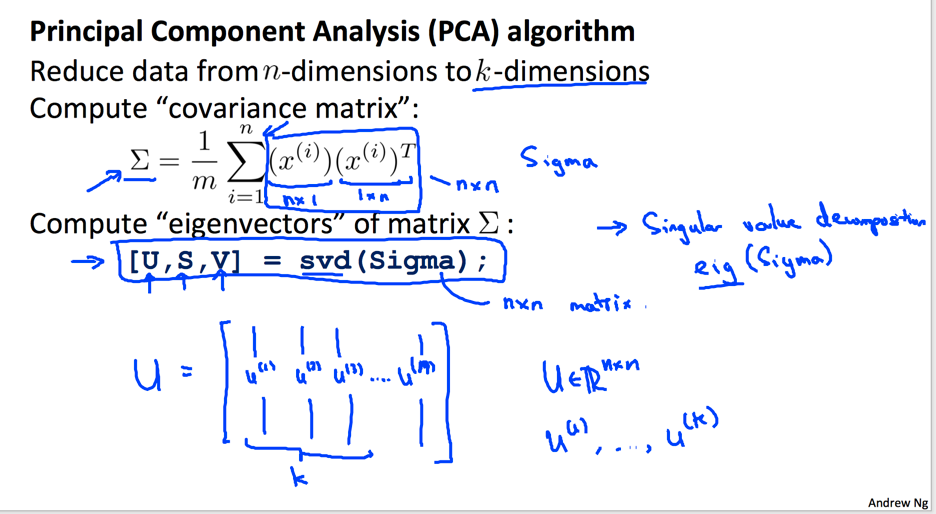
选择的方式是将特征值矩阵的特征值提取出来,累加求和,找到最小接近误差范围的维度:
关于PCA使用的误区:
- 使用PCA来降低overfit。PCA只是更好的近似了原始数据,但并不消灭导致过度拟合的高频信息。即使使用了PAC,原始数据的高频信息还在,并不是解决overfit的本质方法。而应该考虑增加数据量,或者加入regularization等方式。
- 不管三七二十一,一上来就用PCA进行预处理。PCA应该是在原始数据不能有效计算,或者计算量过大的时候再使用,而不是不假思索的使用。
使用PCA之前要先预处理数据:
- 使用mean normalization(处理后,均值为0),这是算法要求。
- 如果不同特征范围偏差较大,需要scale数据,归一化到。(只要是数据之间进行相互融合计算,需要归一化,不然计算不在一个维度)
Anomaly Dection System
Anomaly Dection是一种检测异常数据的算法,其核心思想是对各个可能的特征进行概率分析(高斯分布),然后结合起来考虑概率分布。
假设,个数据都是正常情况下的数据,且每个数据的个特征服从高斯分布,那么新数据也是正常组件的联合概率就是样本的极大似然估计:

其中,;将各个特征的均值和方差设为高斯分布的参数;计算未知数据的联合概率,如果越正常,越大,说明和之前训练用的数据越相似。
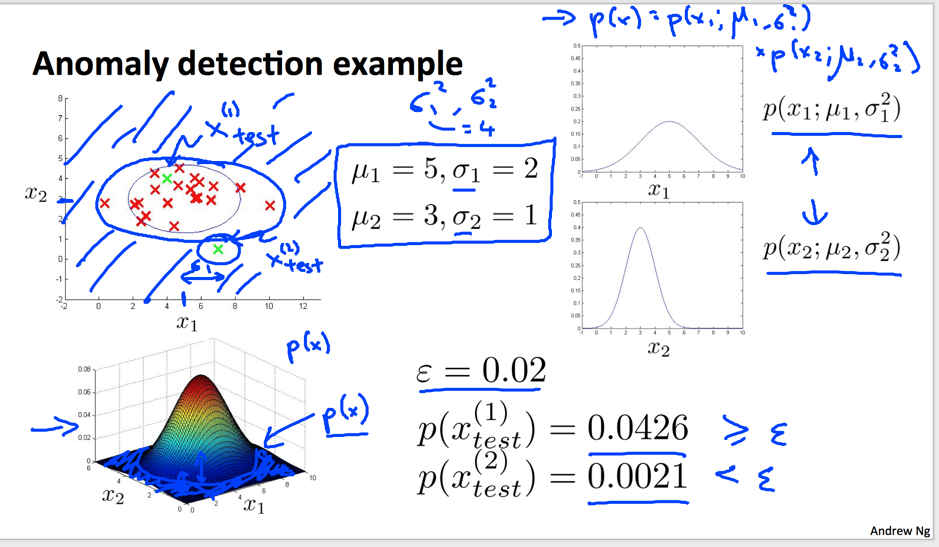
高斯分布简直就是上帝的造物哲学!合并的概率分布也是高斯分布。直观的理解上面计算的结果就是:如果数据和已知标准化的数据越相似(越靠近加权平均的高斯分布中心点),说明数据越可能正常,否则,说明可能不太相似,也就是anomaly.
至于偏差参数的选择,可以基于cv数据评估计算。训练数据都是正常的数据,而cv数据需要有异常数据,否则没有办法有效评估训练结果(好的数据计算得到的似然都很高,丧失了评价意义):

同样,因为cv数据大多数是正常的,也就是skewed数据,所以评估时不能单独考虑accuracy,而需要考虑precision/recall:

这里和上文表述的处理方式一样,都是将认定为不容易出现数据时的类型(不过需要明确,这里其实不是使用标记好的数据,而是非监督学习算法。之所以说明这点,是为了说明True positive对应的习惯含义)。
异常检测算法和监督学习的算法(一元判定)解决的问题很类似,实际使用根据应用场景来定:

总的说来,异常检测算法更突出异常二字。大多数数据都是正常的,只有不多的情况是异常,或者是异常根本无法界定类别(无法打tag),甚至不知道异常长什么样子的情况下,用异常检测更直观有效。或者换个角度来讲,如果数据不能很好的展示异常长什么样子,监督学习算法没办法学到什么是异常,也无从判定异常。
对结果的error analysis重点是分析False Negative的情况(也就是预测不是异常,但其实是异常),这说明我们的模型觉得测试数据和正常数据挺相似,但其实存在一些我们没有考虑到的因素。

将这种情况定性出来,添加到新的特征中。比如上图的CPU负载很高,但是网络没有负载的情况就很异常,是新的特征(may be caused by dead for-loop)
最后,课程中提到了一种全局考虑高斯分布的计算方法Multvariant Guassian Distribution,就不多加整理了。
Recommendation System
推荐系统在现实生活中很常见,比如豆瓣会推荐你可能喜欢的书籍或者电影。该系统的核心目的是:预测用户对某一物品的喜爱程度。
为了更好的分析问题,先分析下输入是什么:
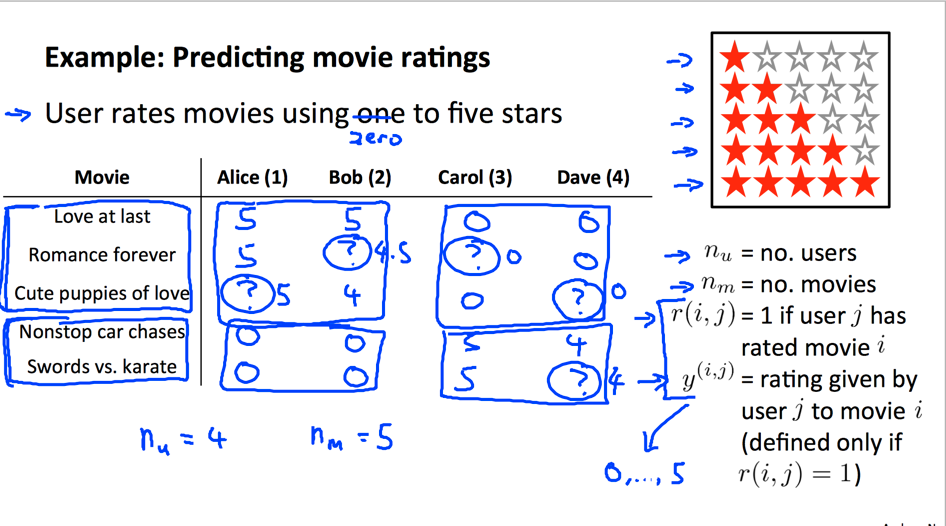
输入其实有两部分:
- 表示物品的特征信息,这和线性回归的输入一样。
- 表示每物品对应的每用户评价。不同的是这里,扩展了一个用户维度。
所以这和一般的线性回归模型不一样,多了一个用户维度。第个用户有不同的权重,我们的任务就是根据这些数据计算出所有的权重,相当于计算所有的。其实计算的方程还是,只是中间多了一个维度而已。
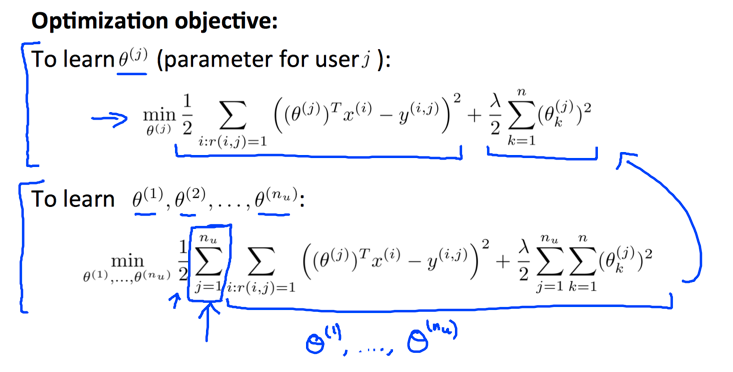
计算时候,将所有参数连接在一起考虑,计算过程等价于遍历矩阵,对其中所有有效的评价进行误差累加。上面的计算过程由于已经知道了商品的特征信息,所以叫做Content-base recommender systems.
但可能的现实情况是根本没有商品的特征信息,而只知道和知道关系公式,那么如何计算?答案就是全都揉在一起优化(优化的本质不就是不知道关系,只知道代价情况下去拟合关系嘛):
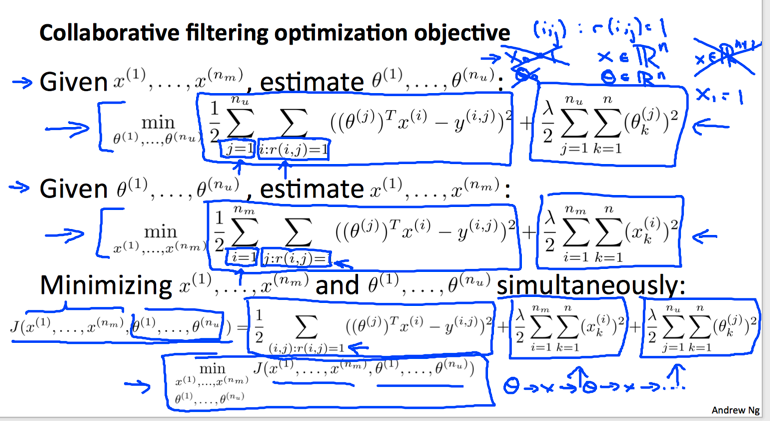
上图的优化方程就是将所有已经标记评分的误差进行累计,然后再对所有参数进行规约处理。注意上图的一个写法,表示对所有评价了的坐标进行遍历。这种融合了几种未知数的算法叫做Collaborative filtering algorithm.
个人觉得该计算方式和K mean挺相似,影响代价的相关参数之间有推导关系,所以可以合起来同时计算,也可以分开来(K mean)单独计算,两种计算方法都可以得到最优解。
没有评价的数据不会影响累积误差的计算,却会因为regularization的原因,导致参数趋于0(参数为0时,对应的regularization项目最小):

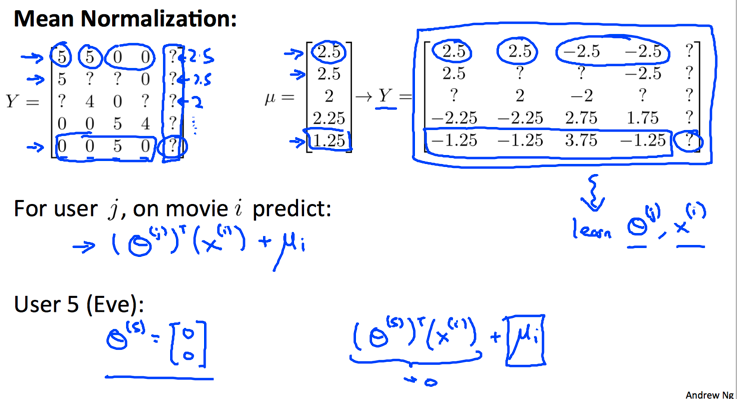
一个好的方法是对数据进行均值归一化处理,这样子,即使没有评分,算出来的参数是0,预估的评分也是0,也就是默认的评分为当前已经评分的默认值。
Using Large Datasets
之前分析的所有算法在数据量很大时,计算量将非常大。因为计算的过程都需要对所有数据统一分析,计算平均信息,比如下图左边的公式:

统一使用所有数据迭代计算的方法叫做Batch gradient descent,其时间复杂度为,这还只是一次迭代的计算复杂度,所以海量数据时,计算量很大。另外一种算法,叫做Stochastic gradient descent则是每次迭代计算只使用一个数据计算偏导数,相比于第一种方法有如下特点:
- 每次只用一个数据计算偏导数,计算复杂度低。
- 相比于batch全局考虑数据(求平均)计算偏导数的方法,新方法可能并不能得到全局最优解,但随着迭代次数的增加,也会不断逼近最优解。
个人感觉,该算法可行的道理有点类似于多次测量求平均值可以优化测量结果的道理。假设我们每一个数据都存在误差(偏离真实情况),但当数据无限多时,其误差一定是呈现正态分布特性。所以当数据无限多时,我们使用平均大法来拟合结果可以得到逼近真实的解。这用来解释上面就是:当我们只使用一个数据来计算模型时,肯定有误差,但当输入数据无限多时,计算结果将会反映一种趋势。所以用无穷多数据不断迭代的结果会越来越逼近真实结果。
还有一种中间形态的模型叫做Mini-batch gradient descent,就是每次使用远远小于m的b$个数据加权计算:
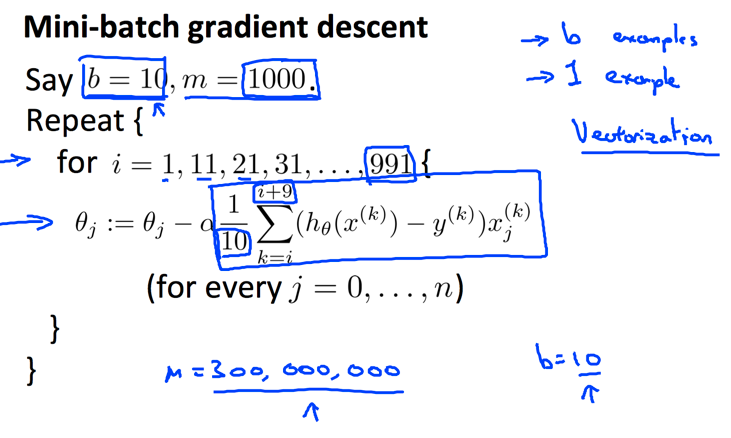
当然,其计算特性也介于两者之间。越大,计算量越大,精度也越高。
迭代过程中,需要记录代价的变化,这可用来分析计算的收敛性。在batch计算模式中,可以计算全局的代价。但在stochastic模式中,没有办法计算全局代价,而是计算当前求解参数情况下,下一个数据的误差代价:

stochastic模式算法非常有效的一个原因是可以处理流数据。每一次用户的点击,每一次用户的操作行为都可以做为一次训练用户偏爱程度的迭代,这种online learning有几个好处:
- 可以处理流数据,不用保存这些海量数据。
- 可以动态的调整计算结果。这对于模型参数可能不断变化的应用场景会更加有效。考虑,用户的口味会随着时代变化而变化。
我觉得该计算模型可能更像人脑的工作模式。我们大脑的每次学习都可以看做接受一个信息,训练,根据反馈结果迭代,那么在迭代特别多次后,形成的知识就比较靠谱有效。