这是自己学习the linux programming interface一书的读书笔记。
chapter 4,5 - I/O模型
UNIX系统设计最精华的地方在于,所有的I/O操作,都可以看成是一个「文件」,这些「文件」公用相同的访问,操作接口,这样子处理业务的逻辑就都可以「抽象成为I/O」的处理。
几个元操作:
- open
- read
- write
- close
- lseek
文件描述符和打开文件之间的关系
内核维护了3个数据结构:
- 进程级别的文件描述符表(open file descriptor)
- 系统级别的打开文件表(open file table),其中的条目叫做(open file handler)
- 文件系统的i-node表
通过open接口得到的整数叫做文件描述符,是一个int整数,只是一个占位符用来定位到具体的一个「文件句柄(open file handler)」的指针。
一个文件句柄中主要记录了:
- 文件的偏移量。
- 文件的访问模式,状态
- 与信号驱动I/O相关的设定
- i-node对象的引用。
而实际的文件对象记录再i-node结构中,其中主要记录文件的类型,权限,等等。
所以实际上,是一个三维的索引结构:「文件描述符 -> 文件句柄 -> i-node」
如果不同的文件描述符(甚至不同进程上)指向相同的文件句柄,那么其实所有操作共享。
如果不同的文件句柄,实际是同一个i-node,那么实际操作是同一个文件,但是可能存在不同的文件偏移和状态,所以可能导致竞态的访问。
dup操作
shell的重定向就使用dup操作,dup的操作就是:「拷贝一个文件描述符对应的句柄到另一个文件描述符上」
其接口格式是:
// 得到新的new_fd,和old_fd公用相同文件句柄 |
还有一个格式是dup2
// 将new_fd作为参数指定,那么创建成功得到新的描述符就是new_fd,就是将特定的文件描述符中的句柄替换了 |
所以将2&>1实现代码就是dup2(1, 2)
系统级别提供了/dev/stdin(stdout/stderr)用来表示虚拟的文件,打开之后得到就是标准I/O的文件。一些程序中只可以从文件名中得到文件,而不是标准输入(可以使用流),这样子就可以解决这个问题:
ls | diff /dev/stdin oldfilelist |
有的程序使用-表示标准输入输出(根据使用情况定),那么可以写成:
ls | diff - oldfilelist |
chapter 58 - socket: TCP/IP 网络基础
地址解析协议(ARP)用来将IP地址映射到MAC地址。 英特网控制协议(ICMP)用来再网络中传输错误和控制信息。
数据链路层中有一个参数很重要:MTU(最大传输单元),表示该层所能传输的帧的大小的上限。
网络层IP层主要做的事情:
- 将数据分割成小的片段,一遍数据链路层进行传输。
- 路由数据。
通配IP地址表示如果一个主机是多宿主的话(有多个对应IP的主机,对应多个网卡),那么所有连接过来的socket都可以匹配到通配IP上。一般通配IP地址是:0.0.0.0
UTP是不知道源主机和目标主机之间的路径MTU的,一般的,基于UDP的程序会采用保守的方法来避免IP进行分段,即确保传输的IP数据报的大小小于Ipv4的组装缓冲区大小的最小值576字节。去掉8个字节记录UDP头信息,至少20个字节保存IP头,所以一般的话使用512字节来存放数据报。 TCP传输的几个重要机制:
- 确认,超时,重传。收到包之后会给发送者确认,同时发送者再发送包之后一段时间如果没有收到确认,就会重传。
- 排序。包有编号,用来再接收方排序,给应用层提供字节流的形式。初始序号(ISN)是随机的。
- 流量控制。发送双方都有一个缓冲区,再开始建立连接的时候,通知对方自己缓冲区的大小,然后发送过程中使用滑动窗口算法控制当前可以发送缓冲区的大小,如果当前接收缓冲区满了,就不在发送。
- 拥塞控制。慢启动和拥塞避免算法。拥塞控制是防止发送者开始的时候大规模的发送数据将网络阻塞。所以慢启动是开始时候小量发送,然后逐渐使用指数级的增量提高发送容量,但是到了一定规模,即估算出的当前网络传输容量阈值的时候,编程线性增加发送容量。
chapter 59 - socket: internet domain
计算机存储整数有大端和小端的区别,大端是内存的低位保存的最高有效位,小端保存最低有效位。如果如果再网络中传输整数(比如ip和port的信息)需要将其编码成统一的字节序,这种字节序叫做网络字节序,它是大段。
特定的API进行转换相关的字节序:
- htons/htonl
- ntohs/ntohl
其中h表示本地的字节序(host),n表示网路(network),最后的s和l表示short和long的版本。
所以如果传输整数的话,需要注意字节序变为网络字节序,当然如果都将整数变为字符串来表示并进行传输,不需要有这个考虑。
一种通用的编码方式是:
- 将所有内容都变为字符串
- 数据项之间使用换行分割
这种格式的编码(服务器对应有该格式的解析)相对比较通用,可以使用telnet调试程序,因为telnet就是发送这种类型的编码数据。
socket连接中使用host和port的新式进行创建,但是一般而言,我们更加习惯使用主机域名和服务名来表示一个服务器的地址。
再os级别有两个映射表
- /etc/hosts: ip和name的映射
- /etc/services: 服务名和port的映射
系统级别有两个函数:
- getaddrinfo: 从域名和服务名得到host和port
- getnameinfo: 从host和info得到域名和服务名
域名到host的过程需要调用DNS服务。DNS服务是一个分布式的数据解析系统。DNS解析的时候按照域名的层级进行一层一层的解析,比如解析域名baidu.com.cn会:
- 先到
cn的节点进行查找,然后该节点会将查询分配到com.cn - 到了
com.cn节点之后,分配到baidu.com.cn的服务器查询 - 最终得到结果,并进行缓存
使用socket建立服务端客户端程序
构建服务端程序的时候需要注意:
需要忽略SIGPIPE信号。这样能够防止服务器再尝试向一个对端已经被关闭的socket写入数据时受到SIGPIPI信号;如果设置的话,write只会反馈EPIPE错误,而不是信号。
通常在监听port的socket上需要设置SO_REUSEADDR选择项,这个参数表示,当当前TCP的该port端口忙,但是TCP状态是TIME_WAIT的时候,依然可以bind成功。这个是因为一个端口释放后两分钟之后才能被使用,如果设置SO_REUSEADDR参数的话,就可以立刻绑定成功。这对于服务器重启后想立刻重启是非常重要的。
提高服务端负载的方式可以使用服务器集群(server farm)
构建服务器集群最简单的一种方法是DNS轮转负载共享(DNS round-robin load sharing),一个地区的域名权威服务器将同一个域名映射到多个IP地址上,这样子可以分担负载。但是也存在问题,其中一个是远端DNS服务器上可能反馈的结果是缓存的IP,这样子就失去了轮询的概念。另外一个如果特定的服务器出了问题,也无妨将其充DNS轮询服务器列表中删除。
一个更加灵活但也更加复杂的解决方案是服务器负载均衡(server load balancing)。这种场景下,一台负载均衡的服务器将客户端请求路由到集群中的其中一个成员上。这样子对外只有一个IP接口,同时可以通过负载均衡器有效的处理无效服务器的情况。
chapter 61 - socket: 高级主题
socket编程需要留意的一个问题是部分读和部分写的问题
如果socket上没有足够的数据(比read需要读取的n个数据小),那么就只能读取部分数据。
在write的时候也存在部分写入的情况:
- write写数据写到一半的时候,被信号中断。
- 工作再非阻塞模式情况下,可能当前只传输了部分的字节。
- 部分数据传输之后出现一个异步错误。比如对端TCP的读取被关闭,或者TCP连接出现问题等。
所以在实际的读写操作中,需要使用循环来读取数据,这样子保证数据可以有效的全部发送和读取出来。
recv()和send()系统调用可在已经连接的套接字上面执行I/O操作,他们比传统的read()和write()系统调用提供了更多的功能:
- 调用中可以指定参数
MSG_DONTWAIT,表示这次的socket读写不阻塞(当然可以再全局上通过fcntl来设置全局的非阻塞模式) - 设定参数
MSG_WAITALL可以让读取操作一定等到指定的字节读取/写入完成之后才返回。但是其实这个设定也并不一定就使得返回的数据等于需要的字节数。因为如果遇到系统受到中断,连接终止,套接字出现错误等情况,都会导致直接被返回。所以还是通过额外的逻辑代码保证最终的效果更加靠谱。 - 设定参数
MSG_MORE,这个参数会使得当前发送的数据会进行栓塞处理。在连续的send操作中,如果设定该参数,那么不会立刻发送TCP的数据,而是等到下一个不设定该参数的send中会将数据发出。(这个设定和全局的TCP_CORK操作是对应的,不过这里是对应再单个操作中,而TCP_CORK是对应全局)
sendfile()系统调用,用来将一个文件读写到另外一个文件中(当然这里强调的是读写到另外一个socket上面)。这比我们单纯的循环read和write要有效的多。因为这样子是会将数据从内核拷贝到用户空间,再用户空间到内核(写入到文件中),效率不高。内核提供的sendfile()操作可以再内核中将数据直接拷贝,效率高。
对sock的fd进行操作的两个接口:
getsockname(): 得到本地socket的地址getpeername(): 得到对端socket的地址
深入探讨TCP的协议
TCP的格式是:
- 首部最多60个字节(4bit的首部长度记录字段,单位是4B,所以最多60)
- 一般首部长度是20字节(如果没有额外的首部参数,只有必要的首部参数)
- 首部具体:
- 2B的源端口号和2B目的端口号
- 4B的序列号
- 4B的确认序列号
- 4bit的首部长度
- 4bit的保留位
- 8bit的控制位
- 2B的窗口大小
- 2B的TCP校验和
- 2B的紧急指针
TCP的状态
TCP使用状态机的方式来维护状态。
状态有很多,对应的关系可以用两个操作来表示:1)连接 2)关闭
连接的情况参考书中的截图:
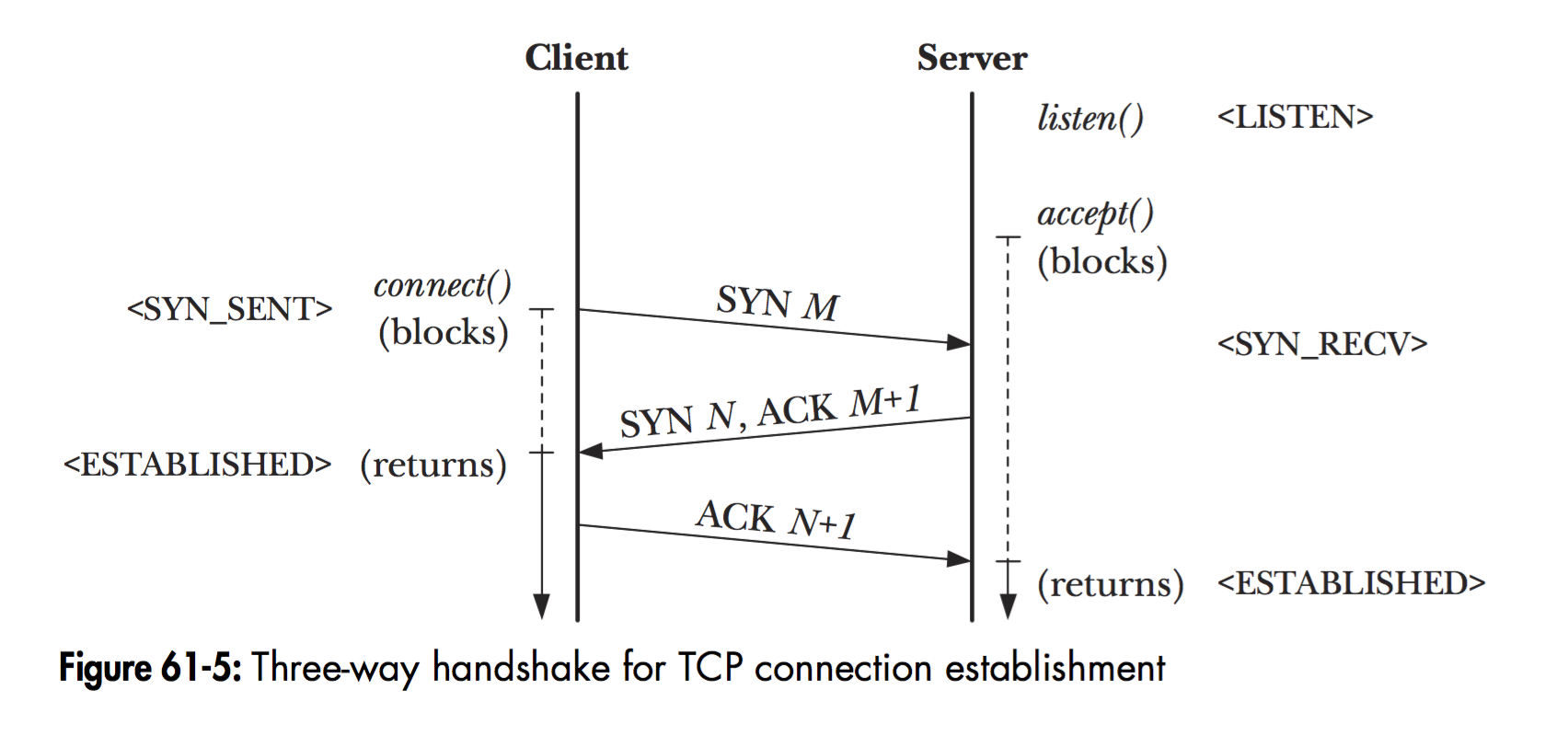
其中三次握手的流程是:
LISTEN状态的服务端等待客户端的连接。- 客户端发送连接进入
SYN_SENT状态,给服务端发送一个syn m的消息,告诉服务度自己包的序号 - 服务度收到
syn m消息之后,进入到SYN_RECV状态,然后给客户端一个ack m+1, syn n消息,表示自己收到了syn m消息,同时确认下一个需要收到的包的ack就是m+1,同时告诉客户端自己的包的编号。 - 客户端收到服务端的
ack m+1, syn n消息之后,进入到ESTABLISHED的状态,并给服务端一个ack n+1的反馈。 - 服务端进入到
ESTABLISHED的状态。
另外一个主要的操作是:关闭连接
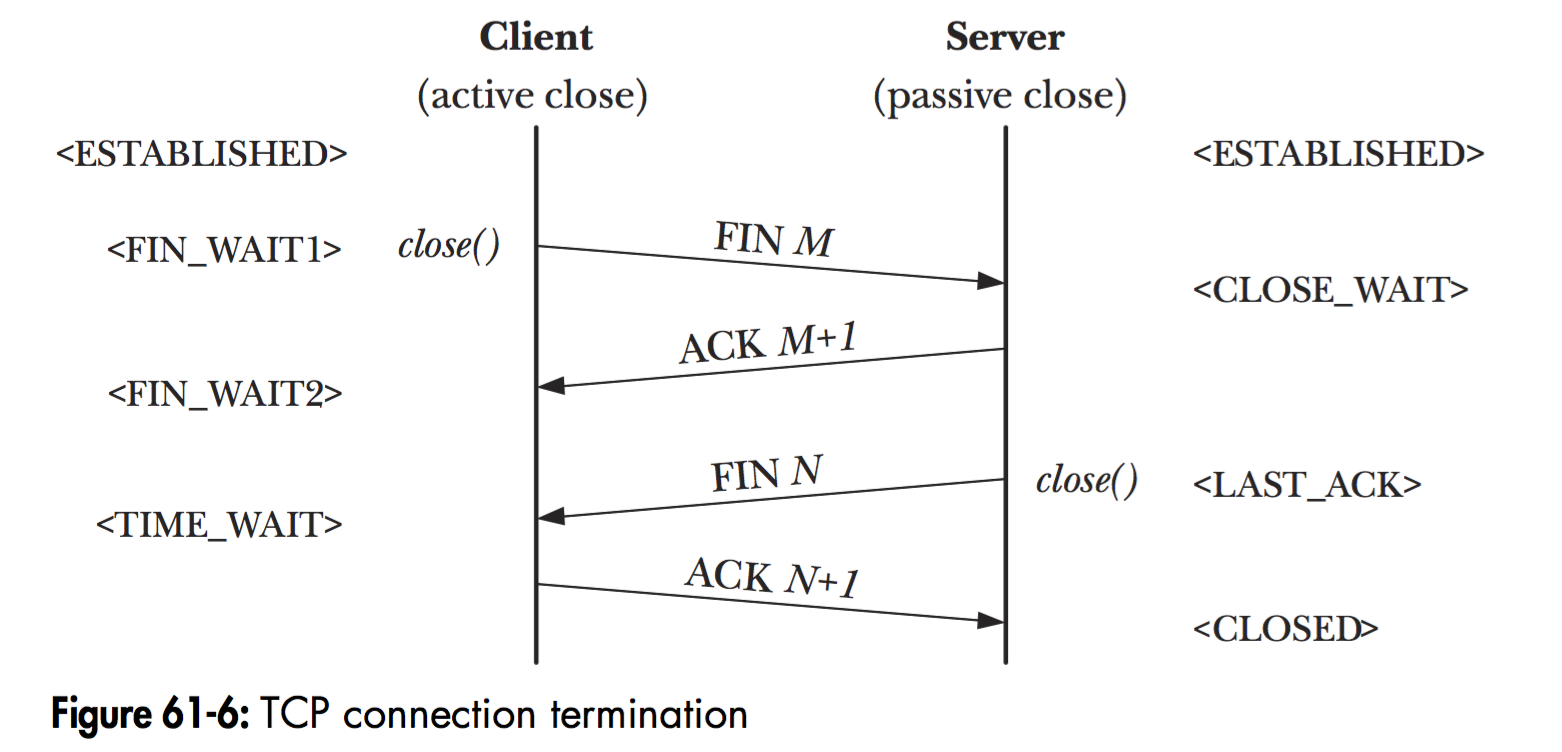
对应的操作是:
- 客户端调用
close()关闭连接,进入到FIN_WAIT1的状态(FIN其实就是finish的意思) - 服务端收到后,进入到
CLOSE_WAIT的状态,然后给客户端一个回执ack - 客户端收到回执ack之后,进入到
FIN_WAIT2状态。 - 这个时候服务端进行一定的
close()之前处理,之后调用close()操作,并给客户端一个FIN,然后自己进入到LAST_ACK状态(应该是等待收到最后一个ack的状态)。 - 客户端收到FIN之后,进入到
TIME_WAIT状态,并且给服务端发送收到FIN消息的ack - 服务端收到客户端的ack之后,进入到
CLOSE状态。 - 客户端会等待**2个MTL(报文最大生存时间)**之后,进入到
CLOSE状态。
只所以要保存一定的时间(就是TIME_WAIT状态),有两个原因:
- 确保连接终止。如果最后的服务端给客户端的ack没有收到,那么服务端会重新发送fin消息,那么客户端再
TIME_WAIT状态下,可以重新发送一个ack。所以2个MTL就是保证第一个ack到客户端的时间(假设更好没有赶上),然后加上服务端重新发送fin的时间。 - 保证老的重复报文失效。因为加入了缓存的时间,这个时间内,不可以重新占用该socket端口,那么旧的数据包就会发送到旧连接中(可以设置
SO_REUSEADDR参数来覆盖wait状态的socket,同时允许使用TIME_WAIT提高可靠性)
netstat
使用netstat参数可以参看系统的socket状态:
netstat -a # 得到当前所有的socket信息,包括监听 |
所以比如查看python写的服务器监听的tcp套接字可以使用:
netstat -alnp --tcp | grep python |
chapter 63 - 其他备选的I/O模型
I/O模型
有三种额外的I/O模型:
- I/O多路复用。允许进程同时检测多个文件描述符,比如
select和poll。其优点是,可移植性,因为在UNIX系统中已经存在了很长时间。缺点是多个文件检测的时候,效率不高。 - 信号驱动I/O。文件可操作的时候,进程接收信号进行处理。
epoll是linux专有的。其提供多路复用,并在同时检测大量文件描述符的时候,提供更好的性能。同信号驱动相比,有几个有点- 避免了处理信号的复杂性
- 可以指定想要检测的事件类型(读就绪或者写就绪)
- 可以选择使用水平触发或者边缘触发来通知进程。
触发机制
讨论一下两种文件描述符准备就绪的通知模式:
- 水平触发。如果文件描述符可以非阻塞地执行I/O系统调用。
- 边缘触发。如果文件描述符自上次检测状态以来有了新的I/O活动(比如新的输入)。
所以,对于水平触发而言,处理代码可以多次进行I/O状态的检测,因为只要可用,就可以反馈。
但是对于边缘触发而言,就不可以这样子。需要再每次触发的时候,尽可能多的执行I/O,不然可能就需要到很久之后的下一次触发才可以继续处理。所以一般会使用循环的方式对文件描述符进行操作(所以这里要求一定是非阻塞的模式),直到没有数据可以操作为止。
select和poll
select系统调用:
- 需要每次调用的时候,将需要监听的文件描述符放入到一个集合set中(这个集合有大小上限,一般是1024大小,由常量
FD_SETSIZE确定,如果需要修改,需要重新编译,oops) - 然后监听之后,内核会修改对应的原始集合,所以返回之后就是监听后就绪的文件描述符的集合(所以需要每次调用select之前都要初始化监听集合)
- 需要制定一个超过所有文件描述符编号的最大编号参数
nfds。因为内核计算的时候,是将所有1到nfds的文件描述符一个个和当前集合进行比对来确定哪一个需要监控的
调用poll和select类似,主要区别在于我们如何制定待检测的文件描述符:
- 传入
结构体(pollfd)的方式,然后监听的时间和触发的返回结果使用单独字段。这样子不需要每次都初始化需要监听的数据结构。 - 需要监听的事件主要有几个:
- POLLIN 监听读事件
- POLLOUT 监听写事件
- POLLPRI 可读取高优先级事件
- POLLHUP 出现挂断
- POLLERR 出现错误
实现层面,两者在linux的实现上都使用了poll本身(一个实现体,其实只是接口设计层面的区别)
两者都存在性能问题:
- 如果检测多个文件描述符时候,需要遍历,效率不高。
- 每次检测,都需要将用户空间下的数据结构拷贝到内核空间中,占用大量CPU时间。
(后面说到的信号驱动I/O和
epoll都使用内核进程记录下感兴趣的文件描述符,所以效率更好)
epoll
epoll的核心数据结构叫做epoll实例。它是内核数据结构的一个句柄,其主要作用是:
- 记录了进程感兴趣的文件描述符列表。
- 维护了处于I/O就绪态的文件描述符列表。(是兴趣列表的子集)
而且这些数据结构都维护在内核中,所以大大提高了效率。监听的事件类似于poll接口,使用掩码的方式进行设置。(所以感觉上是,epoll结构有些面向对象的味道,在内核中维护特定的数据结构,然后通过额外接口进行操作)
还可以设定使用边缘触发的通知机制,类似于信号驱动I/O。不同的是,epoll会合并多次的通知,通过epoll_wait()进行返回,而信号驱动则可能产生多个信号。
设定边缘触发的方式就是在掩码中设定EPOLLET标志:
struct epoll_event et; |
采用边缘触发机制的I/O而言,再收到就绪通知之后,一般的处理逻辑是尽可能多的执行I/O,直到没有数据为止。但是这样子面临一种情况饥饿现象(就是特定I/O一直占据执行,导致后续无法进行监听。或者是因为返回的event list总是有特定顺序,那么总是某个I/O得到相应)
所以为了避免这种问题,大概的处理思路是:
- 维护一个需要执行I/O的优先级队列。
- 队列中的任务可以进行轮转调度,且加入超时机制。
- 队列中任务处理完成之后(比如出现EAGAIN或者EWOULDBLOCK错误码之后),从队列中删除。