学习 go-lang 的笔记,主要的学习站点:
go-by-example
学习一下go by example
switch
switch 可以当做 if/else 来使用, 注意 case 的后面需要加入冒号:
switch { |
另外一个有用的用法,利用 switch 作为 type 的选择器,在 interface 的选择中很有用:
whatAmI := function(i interface{}) { |
slice
数组类型,需要明确指定数组的纬度:
// 数组的纬度记录在类型之前,和一般的语言不太一样 |
如果不指定纬度,就变成了 slice 类型,就是列表,更多可以参考slice-intro
slice 内存结构图: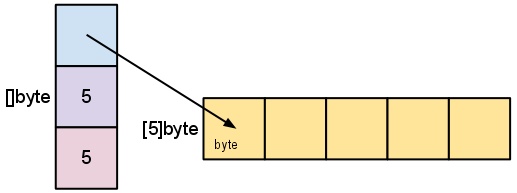
s := []byte{'a', 'b', 'c', 'd'} |
range
go 的 range 操作支持多模态,如果一个参数就是 value 或者是 map 的 key-list,如果是两个,就是 enumerate 的概念,或者是 map 的 items 的概念:
nums := []{1,2,3,4} |
error
go 的 error 机制,类似于 C 的方式,在返回值中透传。个人觉得还是挺好的,可以保持调用函数后,优先判断错误,然后短路返回的调用风格。试的代码逻辑更加健壮,但是一定程度上也增加了冗余.
go 的 error 其实是一个 interface 只要定义对应的Error() string方法签名,就是一个自定义的 error 类:
func (e *argError) Error() string { |
为什么 error 默认都使用指针,根据这个custom-errors-in-golang-and-pointer-receivers的回答。一个可能的考虑点是,使用 error 进行逻辑判定时, 会进行等号检测,需要判定的是 is 概念,而不是值相同的概念。所以,使用指针表示错误,可以直接用等号进行 is 检测。
channel
channel 真是 go-lang 的精髓。
- none-buffer 的通道,必须要有数据等待接受,才可以写入;而 buffer 的通道,可以直接写入,不需要有数据接收。
- 使用 select 可以同步等待多个通道;或者使用default语句,表示等待不到数据的默认选择;或者使用
time.After(time.Seconds)表示等待一定时间的超时。 close一个通道,表示通道内不会再有更多的数据写入,接受通道数据的携程,可以感知这种情况。如果使用for job := range jobs的方式等待通道,会在通道关闭后结束,非常赞的语法糖。使用这个技巧,可以非常容易的实现协程池,多个协程并发的等待队列的工作任务,实现参考worker-pools
func ping(pings chan<- string, msg string) { |
使用WaitGroup做为同步机制,控制多个协程的执行计数:
// 注意使用WaitGroup需要传递指正,因为会修改其数据 |
使用 go 的 channel 阻塞机制,可以很容易的实现令牌桶限流。每隔一段时间就往 channel 中放入令牌,而处理请求时候,必须有令牌才可以放行。基于 channel 的 buffer 机制,可以控制初始的令牌个数:
// 初始个数 |
go 的同步哲学:通过 channel 共享内存,将数据只放在一个协程中进行处理,通过 channel 进行同步。
考虑并发读写请求一个 map,正常的实现是在读写时,給 map 加锁。而 go 的方式是将 map 放在一个状态管理协程中,读写操作都变成任务放入请求队列中,在状态协程处理完毕后,将数据通过通道返回給请求协程。参考stateful-goroutines
// 读请求的任务,需要透传交互用的channel |
module-and-package
go 代码的组织关系按照:repo --> module --> package 的方式进行组织管理。在代码的 repo 根目录下需要配置go.mod,记录当前库的前缀:
module github.com/whiledong/test |
这样子,等于在该 repo 中写的代码都有这个全局的前缀限定符。在 repo 中建立的每一个目录或者子目录,都是在该 module 前缀后扩展。go 的目录名称要和 package 的名称一致。import 代码的级别是 package,而项目输出的级别是 module。
如果使用go install命令,安装的执行程序放在$GOPATH/bin/test中,等于 module 限定符的最后一部分就是程序级别的输出名字。
对于 go 而言,package 的名称和 package 所在的目录名,基本上,除了是 main 的 package,别的情况下都最好要一致:
- go 使用路径名进行 import 的导入
- 导入后,使用对应路径下的 package 名称做为导入的包前缀
所以如果不一致,就会发现导入的路径名称和使用的包名称不一致,比较奇怪。everything-you-need-to-know-about-packages-in-go
effective-go
记录effective-go的学习内容。
-
在package定义之前的是包级别的注释,一般定义为
Package xxxx implements xxxx -
对外暴露的接口,一般注释第一个单词就是方法名称,比如:
// Compile parses a regular expression and returns, if successful,
// a Regexp that can be used to match against text.
func Compile(str string) (*Regexp, error) {这样子对grep比较友好,搜索关键字,就知道第一个单词对应方法名。
-
package的名称,在go中提倡更加简单,简洁的方式。
Long names don't automatically make things more readable. A helpful doc comment can often be more valuable than an extra long name.。 -
Go has no comma operator and ++ and – are statements not expressions. Thus if you want to run multiple variables in a for you should use parallel assignment (although that precludes ++ and --).
在for语句中,如果需要同时操作多个数据的变更,使用tuple的变更方式:
// Reverse a
for i, j := 0, len(a)-1; i < j; i, j = i+1, j-1 {
a[i], a[j] = a[j], a[i]
} -
go中支持,返回的参数带名称,和入参一样,带名称的参数会初始化为zero values of type. 如果return没有加入参数,会返回命名返回参数的当前数值。
func ReadFull(r Reader, buf []byte) (n int, err error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
return
} -
go的defer语句,会在调用defer之时,就会计算defer函数绑定的参数内容。和一般语言的闭包延迟解析机制不太一样,应该算是避免了一种可能的语言坑。
// LIFO: last in first out, output: 4 3 2 1
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}defer的参数,在defer调用时解析,利用好可以简化代码逻辑,比如文档中给出的:
/*
entering: b
in b
entering: a
in a
leaving: a
leaving: b
*/
func trace(s string) string {
fmt.Println("entering:", s)
return s
}
func un(s string) {
fmt.Println("leaving:", s)
}
func a() {
defer un(trace("a"))
fmt.Println("in a")
}
func b() {
defer un(trace("b"))
fmt.Println("in b")
a()
}
func main() {
b()
}trace在调用defer的过程中,起到了初始化的作用,一行代码做到了context的开始和运行log的监控。 -
slice的本质其实是包含了数据指针的结构体,使用值传递,但是在修改slice内容的时候,会修改到内部的数据。所以,我们可以用slice做为入参时,可以修改实际的数据,比如File.Read的定义func (f *File) Read(buf []byte) (n int, err error)。 -
2D-slice的分配有两种方式(体现了go的灵活),一种是数据可变长的,每次分配一个新的行数据;另外是类似C的方式,二维的数组数据本身就是一个一维数组,这样子内存效率更高:// Allocate the top-level slice.
picture := make([][]uint8, YSize) // One row per unit of y.
// Loop over the rows, allocating the slice for each row.
for i := range picture {
picture[i] = make([]uint8, XSize)
}
// 将行数据指向一个数据段分片
// Allocate the top-level slice, the same as before.
picture := make([][]uint8, YSize) // One row per unit of y.
// Allocate one large slice to hold all the pixels.
pixels := make([]uint8, XSize*YSize) // Has type []uint8 even though picture is [][]uint8.
// Loop over the rows, slicing each row from the front of the remaining pixels slice.
for i := range picture {
picture[i], pixels = pixels[:XSize], pixels[XSize:]
} -
使用
String() string接口时,需要留意不要产生类型数据的循环解析:type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", m) // Error: will recur forever.
}解决的方法很简单,将数据强制转换为基本类型:
type MyString string
func (m MyString) String() string {
return fmt.Sprintf("MyString=%s", string(m)) // OK: note conversion.
} -
The rule about pointers vs. values for receivers is that value methods can be invoked on pointers and values, but pointer methods can only be invoked on pointers. This rule arises because pointer methods can modify the receiver; invoking them on a value would cause the method to receive a copy of the value, so any modifications would be discarded. The language therefore disallows this mistake.
指针定义的方法,就表示数据是可变的,只能接受指针数据。
-
go中没有继承的概念,继承通过
embedding来实现。所谓embedding就是直接将父类的方法和字段变成自己的方法和字段,提供了一种更加类型(接口)组合方式:// io.ReadWrite就是一个接口的组合,直接包含了Reader/Write的接口方法
// ReadWriter stores pointers to a Reader and a Writer.
// It implements io.ReadWriter.
type ReadWriter struct {
*Reader // *bufio.Reader
*Writer // *bufio.Writer
}注意,
embedding不需要制定变量名称,如果制定了,就不是嵌入,而是定义成员变量,这样子还需要自己定义相关的方法实现,才算是有对应的接口:type ReadWriter struct {
reader *Reader
writer *Writer
}
// 还需要自己重新实现对应的接口方法
func (rw *ReadWriter) Read(p []byte) (n int, err error) {
return rw.reader.Read(p)
}对于
embedding而言,其和继承不同的地方就在于,调用embedding类型的方法时,实际是一种组合的关系,会将方法委托到对应的实例方法上,就类似上面的代码实现。同时我们可以再构造的时候,制定组合的对象:
type Job struct {
Command string
*log.Logger
}
func NewJob(command string, logger *log.Logger) *Job {
return &Job{command, logger}
}
// or with a composite literal
// job := &Job{command, log.New(os.Stderr, "Job: ", log.Ldate)}可以使用最里面的类名称做为实际的组合对象进行返回,比如:
func (job *Job) Printf(format string, args ...interface{}) {
job.Logger.Printf("%q: %s", job.Command, fmt.Sprintf(format, args...))
}如果嵌入的类名称或者相同层级的字段相同的话,只要外围不直接使用冲突的名称,系统不会报错,因为只需要扩展方法和属性而已,否则会报错。
if the same name appears at the same nesting level, it is usually an error; it would be erroneous to embed log.Logger if the Job struct contained another field or method called Logger. However, if the duplicate name is never mentioned in the program outside the type definition, it is OK. This qualification provides some protection against changes made to types embedded from outside; there is no problem if a field is added that conflicts with another field in another subtype if neither field is ever used.
-
go的并发设计哲学:
Do not communicate by sharing memory; instead, share memory by communicating.
go强大的concurrent的工具,天然可以用作生产者-消费者模式的处理队列,比如文档中提到的
A Leaky Buffer示例。该例是RPC框架的一个抽象,客户端(这里类producer)不停读取网络数据,获取到数据后,放入有界空闲队列中,起到了缓存池的作用。处理完数据后,放入空闲池中,等待一个服务端(这里类consumer)来消费,使用一个无缓存的channel进行空闲Buffer的传递(个人理解:如果处理方比较繁忙,生产方可以直接休息,而不用接受更多的生产需求,所以使用无缓存的channel在这里有这样一层控制语义)
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// Grab a buffer if available; allocate if not.
select {
case b = <-freeList:
// Got one; nothing more to do.
default:
// None free, so allocate a new one.
b = new(Buffer)
}
load(b) // Read next message from the net.
// 无缓存channel,也可能能有多个协程等待,只是只能一个被唤醒
serverChan <- b // Send to server.
}
}func server() {
for {
b := <-serverChan // Wait for work.
process(b)
// Reuse buffer if there's room.
select {
case freeList <- b:
// Buffer on free list; nothing more to do.
default:
// Free list full, just carry on.
// 这里可能存在,存在满池的情况:server处理非常满,client处理很快,
// 又将数据填满freeList的buffer,上一轮处理的数据就放不回去了
}
}
} -
panic不要轻易使用,更多的使用error进行错误的处理。一种使用panic的场景是用在init函数中,如果初始化时候数据状态不对,直接退出程序是一个不错的选择:var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
} -
关于interface-and-methods,文档中的例子非常生动:
在go中,任何类型都可以绑定方法,所以任何的东西在go中都可以满足接口的要求,比如
http.Handler接口:type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}这里,
ResponseWriter是一个接口,实现了Write方法,一般接口在go中都直接使用值类型;而Request是一个结构体,所以这里使用指针类型。如果需要保存状态,比如容易想到,使用结构体,定义状态数据,并实现接口方法:
// Simple counter server.
type Counter struct {
n int
}
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
ctr.n++
fmt.Fprintf(w, "counter = %d\n", ctr.n)
}但实际上,这里其实直接用int就可以表示
Counter类型:// 直接int表示类型,实现对应方法,很有意思
// int本身就记录了自身的状态
type Counter int
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
*ctr++
fmt.Fprintf(w, "counter = %d\n", *ctr)
}如果需要访问网页的时候,存在一些通知事件,可以将channel直接作为类型定义:
// A channel that sends a notification on each visit.
// (Probably want the channel to be buffered.)
type Chan chan *http.Request
func (ch Chan) ServeHTTP(w http.ResponseWriter, req *http.Request) {
ch <- req
fmt.Fprint(w, "notification sent")
}最后,如果我们打算将符合签名的原始方法,转化为无状态的实现
ServeHTTP的类型,可以直接将 函数 定义为一个类型,调用该类型就等于进行函数的强制转换:// The HandlerFunc type is an adapter to allow the use of
// ordinary functions as HTTP handlers. If f is a function
// with the appropriate signature, HandlerFunc(f) is a
// Handler object that calls f.
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, req).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, req *Request) {
f(w, req)
}
// Argument server.
func ArgServer(w http.ResponseWriter, req *http.Request) {
fmt.Fprintln(w, os.Args)
}
http.Handle("/args", http.HandlerFunc(ArgServer))总结起来:
- go中接口就是方法的集合
- 几乎go中任何元素都可以定义为一个type
- type不一定只能用struct来包含状态,元素本身就可以作为type的状态
- type本质上是嫁接数据和接口的桥梁
misc
slices-of-interfaces
go 中为什么,[]T的 slice 不可以强转换为[]interface{}:因为interface{}对象,实际上包含 2 个信息,一个是数据本身,一个是具体的类型(这样子才有运行时的反射和动态类型解析)。但普通类型T的对象,是不需要动态类型解析的,其类型只存在于编译期。
所以,在 go 中如果这样子转换,需要O(n)时间复杂度,而在 go 的设计哲学中,语法是不能够隐藏复杂度,所以需要手动实现,利用反射的一个实现代码:
func InterfaceSlice(slice interface{}) []interface{} { |
- 具体参考 stackoverflow 的回答type-converting-slices-of-interfaces
- golang 官方的说明go-wiki-interface-slice
- 非常好的介绍 interface 的疑点how-to-use-interfaces-in-go
formatting
go 中几个有用的,和别的编程语言不太一样的格式控制符:
%v:打印 go 类型的基本表示。%+v:打印 struct 时,加入 filed 名称。%#v:打印 struct 时,同时加入 struct 的名称和 filed 名称。%T:打印类型
goproxy
大陆的官方本地代理服务,go的package挂载CDN,具体参考项目主页goproxy.cn
在mac中需要配置环境变量:
export GO111MODULE=on |